老板让做一篇基础的协程分享介绍. S O W H Y C O R O U T I N E
在我们之前的文章 “为什么线程” 中, 讨论了线程的概念: 一个线程对应一个执行流. 增加一个线程意味着增加了一条逻辑执行流, 从而增强了应用的表达能力和处理能力. 当应用编写完逻辑执行流后, 负责为每条逻辑执行流创建对应的线程, 而内核则负责将这些线程调度到具体的 CPU 上执行, 以推动逻辑流的前进. 但是, 逻辑执行流与线程这种 1:1 的关系是否是最优的呢?这通常取决于应用场景.
对于 CPU 密集型场景, 1:1 对应关系较为合适, 因为这些场景下逻辑执行流不会频繁进入内核态. 内核的公平调度机制能确保每个线程都获得公平的 CPU 调度机会, 保证每一条逻辑执行流都能平稳前进, 不会因为缺乏调度而被阻塞. 关于内核的公平调度器, 你可以参考 Linux 中的 PELT 的系列文章.
反之, 在 IO 密集型场景中, 逻辑执行流频繁进入内核态等待 IO 准备, 这种 1:1 的对应关系可能导致频繁的内核态与用户态切换, 从而影响应用性能. 为了解决这个问题, 可以采用多对一 (M:1) 的关系, 将多个逻辑执行流对应一个线程. 这种情况下, 应用在编写逻辑流后, 会为每个逻辑流创建一个协程结构, 然后为这些协程选择运行线程. 当协程需要等待某件事件就绪时, 比如 IO, 其并不需要陷入内核态, 而是将控制权转交给线程中的用户态调度器, 此时线程也不会陷入内核态, 而是从其维护的可运行协程队列中选择其他协程执行. 即内核的公平调度器在适当的时候调度线程到 CPU 上运行, 而位于线程中的用户态调度器会从可运行的协程队列中选择一个协程执行. 如下图所示:
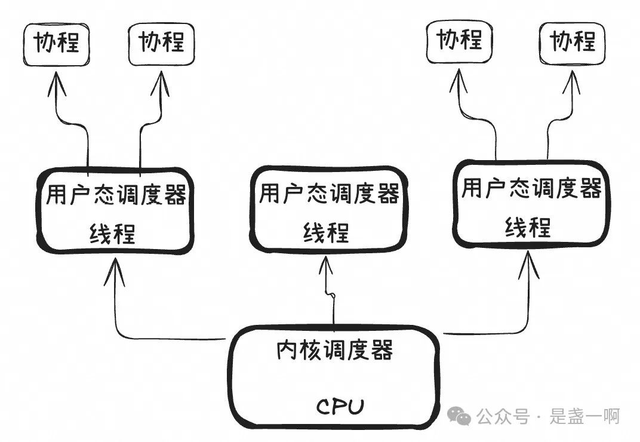
然而, 在 M:1 关系中, 可能会出现线程负载不均的情况. 例如, 大多数协程可能被分配给某一个线程, 或即便协程分配均匀, 其内部逻辑却不同, 导致一些线程处于空闲状态. 为此, 引入了 M:N 关系, 这时应用负责编写逻辑流并为逻辑流创建一个协程结构, 之后将协程扔给用户态运行时调度器, 用户态运行时调度器维护一组工作线程, 负责将协程调度到不同的线程时执行, 当工作线程空闲时, 它会尝试从其他线程的可运行协程队列中“偷”协程来运行. 这样, 协程在其生命周期内可能在多个线程中执行. 关于 M:N 关系的更多信息, 你可以参考我在 cpp-submit 的演讲 PPT “异步编程与协程在高性能实时数仓 Hologres 的实践”.
python coroutine
python asyncio 实现了我们上面所说 M:1 调度关系. 这里 asyncio.Task 对应着我们上面提到的协程结构. event loop 则对应着上面提到的 “位于线程中的用户态调度器”. 对于常规的业务开发, 只需要利用 async/await 语法编织逻辑执行流, 之后通过 create_task 为逻辑执行流创建对应的协程结构即可. 这里 async 负责定义 coroutine function, 在 coroutine function 内可以执行其他异步操作, 并使用 await 来等待这些异步操作的结果, 若此时异步操作结果已经就绪, 则 await 返回该结果, 执行流继续往下推进; 若此时异步操作结果尚未就绪, 则当前 Task 会被挂起, 线程会调度下一个可运行的 Task 执行.
import socket, asyncio, logging
logging.basicConfig(format="%(asctime)s|T=%(thread)d|%(message)s", level=logging.INFO)
logger = logging.getLogger("zytest")
loop = asyncio.new_event_loop()
async def server_main(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.setblocking(False)
sock.bind((host, port))
sock.listen()
while True:
client_sock, addr = await loop.sock_accept(sock)
logger.info(f'server_main: Connection from {addr}')
loop.create_task(client_main(client_sock))
async def client_main(sock):
while True:
received_data = await loop.sock_recv(sock, 4096)
if not received_data:
break
logger.info(f'client_main {sock.getpeername()}: recv {received_data}')
send_fut = loop.sock_sendall(sock, received_data)
await send_fut
#logger.info(f'client_main {sock.getpeername()}: send {received_data}')
logger.info(f'client_main {sock.getpeername()}: disconnected')
sock.close()
if __name__ == '__main__':
loop.create_task(server_main())
loop.run_forever()
-
server_main,client_main是 Task 的入口函数, 我个人倾向于在函数名中包含 main 来表明她们与常规 coroutine functions 的区别. send_fut = loop.sock_sendall(sock, received_data),- 这里会执行异步操作
loop.sock_sendall,loop.sock_sendall内会执行sock.send(received_data), - 若能在这次
sock.send中成功将 received_data 全部写入到内核缓冲区, 则此时 send_fut 为就绪状态, 接下来的await send_fut不会导致当前 Task 挂起. - 反之若由于内核缓冲区满等原因导致
sock.send(received_data)不能将 received_data 全部写入, 则此时 send_fut 为非就绪状态,- 接下来的
await send_fut会挂起当前 Task. 此时 loop 会调度下一个可运行的 Task. - 同时 loop 也会利用内核提供的设施, 在 sock 对应内核缓冲区有空闲时再次调度 client_main Task 运行.
- 每次 client_main Task 被调度运行时, 其会执行
sock.send来发送剩余数据, - send_fut 会在全部数据发送完成之后变为就绪状态, client_main Task 执行
await send_fut然后继续执行下一条指令.
- 接下来的
- 这里会执行异步操作
loop.create_task(client_main(client_sock)), 可以看到 server_main Task 会为每一个链接创建对应的 client_main Task. 如之前描述, 这些 Task 都运行在同一个线程中, 由线程内的 loop 负责调度可运行的 task.
2024-11-10 06:41:46,768|T=140095312799552|server_main: Connection from ('127.0.0.1', 54030)
2024-11-10 06:41:50,791|T=140095312799552|client_main ('127.0.0.1', 54030): recv 'client1'
2024-11-10 06:41:54,059|T=140095312799552|server_main: Connection from ('127.0.0.1', 54084)
2024-11-10 06:41:55,249|T=140095312799552|client_main ('127.0.0.1', 54084): recv 'client2'
2024-11-10 06:42:16,155|T=140095312799552|client_main ('127.0.0.1', 54030): recv 'client1_1'
2024-11-10 06:42:20,900|T=140095312799552|client_main ('127.0.0.1', 54084): recv 'client2_1'
async for/async with
async for, async with 语法糖都是基于 await 能力构建, 语义上等同于 for/with 的异步版本. 比如:
async for TARGET in ITER:
SUITE
else:
SUITE2
# 等同于如下结构:
iter = (ITER)
running = True
while running:
try:
TARGET = await iter.__anext__()
except StopAsyncIteration:
running = False
else:
SUITE
else:
SUITE2
同步调异步
coroutine 一个令人诟病的地方在于其传染性. 假设你现在有一个函数 F, 她想执行某个异步操作 AsyncOp, 那么 F 必须要 await AsyncOp(), 那么 F 在定义时也必须使用 async def, 那么 F 所有调用者都必须修改为 await F(), 进一步所有调用者都必须改为 async def…
现在假设你已经有一个成熟的对外暴露的接口 F, 你现在需要更改 F 的实现, 引入某个三方库 L, 该库 L 只提供了 coroutine 接口, 那么这时可以利用 loop.run_until_complete.
async def L():
await asyncio.sleep(3)
def F():
loop = asyncio.get_event_loop()
L_fut = L()
loop.run_until_complete(L_fut)
return
async def G():
loop = asyncio.get_event_loop()
loop.run_until_complete(L())
await asyncio.sleep(0)
loop.run_until_complete 会阻塞当前线程, 直至 L_fut 变为就绪状态. loop.run_until_complete 一定要在同步异步的边界处使用, 在异步代码中使用 loop.run_until_complete 将导致异常:
>>> loop.run_until_complete(G())
Traceback (most recent call last):
...
RuntimeError: This event loop is already running
异步调同步
loop 提供的是协作式调度, 她仅在每个协程逻辑执行流主动让出对线程的占有时才有机会调度其他协程执行. 因此如果需要在 coroutine 中执行 cpu-bound 操作, 或者某些现存的同步 io 操作, 为了避免阻塞其他协程调度运行, 需要利用 loop.run_in_executor.
# https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.loop.run_until_complete
def blocking_io():
# File operations (such as logging) can block the
# event loop: run them in a thread pool.
with open('/dev/urandom', 'rb') as f:
return f.read(100)
def cpu_bound():
# CPU-bound operations will block the event loop:
# in general it is preferable to run them in a
# process pool.
return sum(i * i for i in range(10 ** 7))
async def main():
loop = asyncio.get_running_loop()
## Options:
# 1. Run in the default loop's executor:
result = await loop.run_in_executor(None, blocking_io)
print('default thread pool', result)
# 2. Run in a custom thread pool:
with concurrent.futures.ThreadPoolExecutor() as pool:
result = await loop.run_in_executor(pool, blocking_io)
print('custom thread pool', result)
# 3. Run in a custom process pool:
with concurrent.futures.ProcessPoolExecutor() as pool:
result = await loop.run_in_executor(pool, cpu_bound)
print('custom process pool', result)
线程安全
若不特殊说明, asyncio 提供的所有操作都不是线程安全的, 这些操作都应该发生在 loop 所在线程. 如果需要从其他线程往 loop 所在线程递交任务, 可以利用 loop.call_soon_threadsafe 等机制:
# https://docs.python.org/3/library/asyncio-dev.html#asyncio-multithreading
async def coro_func():
return await asyncio.sleep(1, 42)
# Later in another OS thread:
future = asyncio.run_coroutine_threadsafe(coro_func(), loop)
# Wait for the result:
result = future.result()
事前防御
内核中的公平调度器提供的是抢占着调度能力, 在线程调度到具体的 CPU 上执行一段时间之后, 即使这个线程对应的逻辑执行流仍有指令可以继续执行, 内核也会强行挂起当前执行线程, 转而从可运行队列中选择下一个线程来调度其到 CPU 上运行. 而位于线程中的用户态调度器提供的是协作式调度, 她仅在每个协程逻辑执行流主动让出对线程的占有时才有机会调度其他协程执行. 所以经常会出现的一个问题是, 某个协程占据线程时间过长, 导致处于可执行队列中的其他协程得不到运行时机, 这种情况在 asyncio 这种 M:1 对应关系下更为严重. 所以这里事前防御便是要求每一位业务开发要记得协作.
尽管如此, 我并不打算详细介绍如何编写对协程更友好的代码, 我个人认为这个对开发人员心智负担就太大了, 每写一行还得思考对其他协程, 对调度运行时的影响. 正如我在 C++ 异常与 longjmp: 缘起, 没有想象中那么美好, 比想象中还要遭, 尘埃落定 所做的努力一样, 我个人倾向于通过完善的 CI 流程以及稳健的用户态调度运行时来解决问题, 在 CI 流程中, 可以通过 lint 工具, 比如 python 的 ruff check, c++ 的 clang-tidy 等. 这样开发人员只需要负责让代码能通过 CI 即可. 但简单来说, 为写出写成友好代码要记住的点也不是很多:
-
记得适当的时候
await asyncio.sleep(0), 比如在一个很长的 for loop 中,await asyncio.sleep(0)可以让当前 Task 主动让出线程, 使得其他协程可以被调度. -
即使业务逻辑中已经有 await 了, 也应在适当的时候
await asyncio.sleep(0). 在类似 rust tokio 等成熟的用户态调度器中, 每一个 Task 都有一个 budget 概念:
Even though Tokio is not able to preempt, there is still an opportunity to nudge a task to yield back to the scheduler. As of 0.2.14, each Tokio task has an operation budget. This budget is reset when the scheduler switches to the task. Each Tokio resource (socket, timer, channel, …) is aware of this budget. As long as the task has budget remaining, the resource operates as it did previously. Each asynchronous operation (actions that users must .await on) decrements the task’s budget. Once the task is out of budget, all Tokio resources will perpetually return “not ready” until the task yields back to the scheduler. At that point, the budget is reset, and future .awaits on Tokio resources will again function normally.
但 python asyncio 没有这类机制, 这对某些场景不是很友好, 比如在如下 case 中.
q = asyncio.Queue()
async def task1():
while True:
req = await get_req_from_connection()
do_something(req)
await q.put(req)
async def task2():
req = await q.get()
do_something2(req)
在压测场景中, 在 get_req_from_connection() 总是处于就绪状态时, await get_req_from_connection() 并不会挂起 task1, 而 q 在定义时未指定 maxsize, 所以 await q.put(req) 也总不会挂起 task1, 这导致 task2 很难得到调度机会. 而在 tokio 中, 由 budget 机制可以强制 task1 在 await 点让出线程, 即使 await 对应的异步操作已经执行结束. 对此与 python 社区进行过一次讨论, 但社区对此兴致泛泛.
事后追踪
事后追踪关注的则是万一坏情况发生了, 应用响应不符合预期了, 我们怎么来定位是哪个坏协程在捣蛋? 这就需要一个稳健的用户态调度运行时了.
调度运行时一个可做的事情是: 周期性检测所有工作线程运行情况, 如果发现某一线程一直在执行一个协程, 则调度系统可以给这个线程来个 SIGUSR2 信号, 工作线程在 SIGUSR2 信号处理函数中调用 backtrace 保存下当前堆栈便于后续研发同学针对性排查修复. 这其实并不是一个很好的办法, 主要是在信号处理函数执行 backtrace 这么复杂的事情要非常的讲究! 我在实际线上就遇到过这些问题: backtrace() crash: 从 CFI 说起, 递归锁并不递归 等. 但好在也只遇到过这些小问题, 而且这一方案确实帮我们解决了不少线上问题.
调度运行时另一个可做的事情是完善的 metric 指标, 这块就比较直观, 直接借鉴 Linux 内核针对 scheduler 的指标设计即可. 这里我们可以将用户态位于线程中的用户态调度器与内核中 struct rq 对应起来, 将协程结构与 struct task_struct 对应起来, 仿照着 CONFIG_SCHEDSTATS 对应的内核指标建立我们对应的用户态 metric 指标即可. 比较值得关注的指标有: 可运行队列的长度, 协程从可运行到真正运行的延迟分布等.
正如 “异步编程与协程在高性能实时数仓 Hologres 的实践” 提到的还有一个可做的事情是, 针对用户态运行时的特点, 利用 gdb python script 能力扩展 gdb, 比如异步堆栈的展示, 可运行队列中的展示等. 类似于常规多线程调试常用的 info threads, thread apply all bt 等能力.