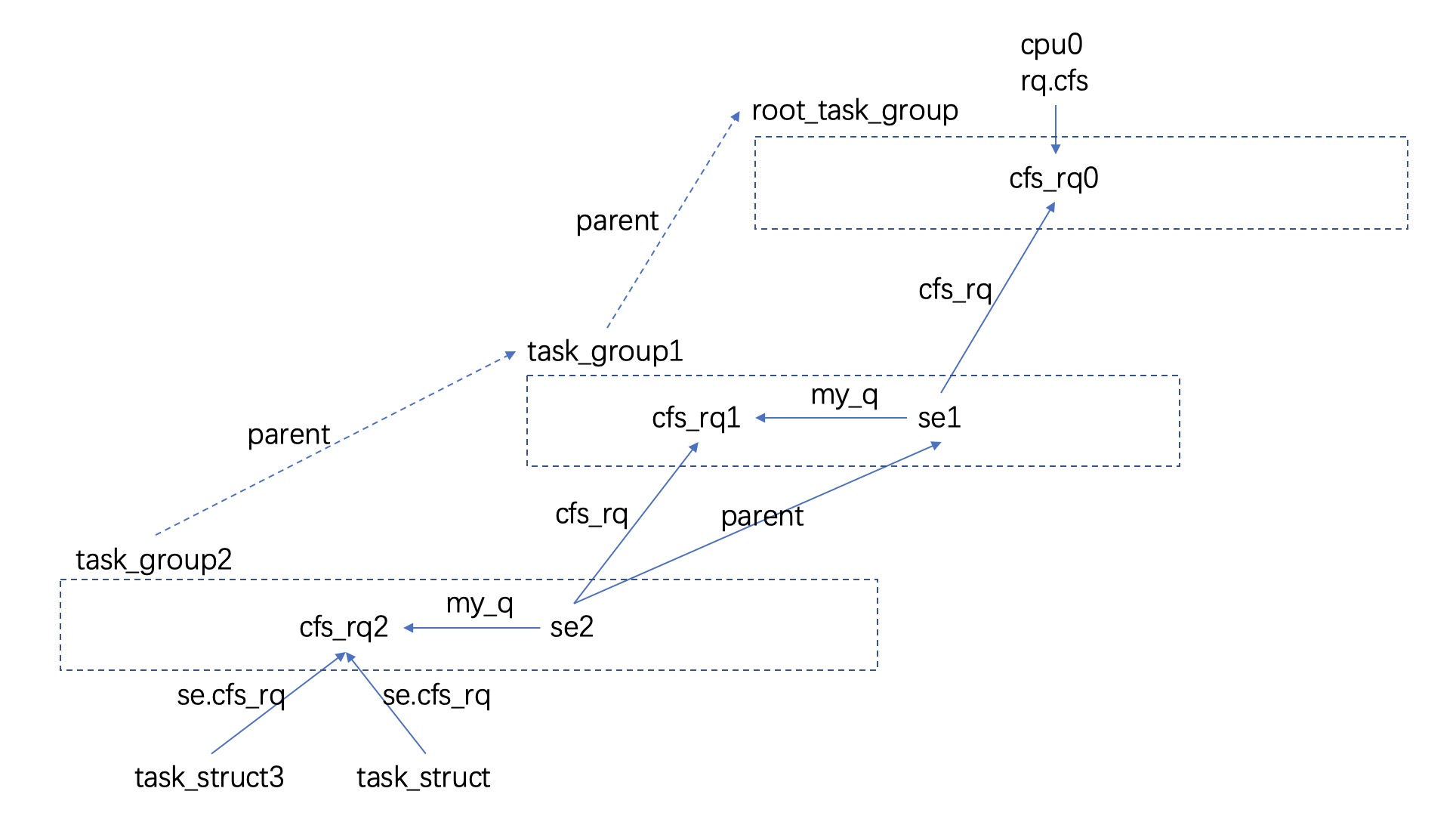
本文基于 linux 5.16, 本文不是 linux pelt 入门介绍, 而是我在了解完 pelt 之后一些猜测推断与整理, 希望能与大家交流化解下我的迷惑. 本文使用的 task group 结构如下所示:
task_struct se pelt
对于一个单独的 task_struct pe pelt 计算, 当前内核采用的公式是:
\[{w_n * t_n * y ^ n + w_{n-1} * t_{n-1} * y ^ {n-1} + ... + w_1 * t_1 * y ^ 1 + w_0 * t_0 * y ^ 0 } \over { W * y ^ n + W * y ^ {n-1} + ... + W * y ^ 1 + W * y ^ 0 }\]此时 W 是 pelt 时间窗口, 1024us, t 为时间窗口为 task_struct 活跃时长; w 算是权重, linux 认为 nice=-20, nice=19 的进程运行同样的时间造成的 load 是不一样的, 这个我可以理解, 毕竟如果不加 w, 那么对于一个 cpu, 其上 load 就取决于其上可运行进程的个数, 也即负载均衡将仅根据可运行进程的个数来进行均衡, 即负载均衡认为的 “均衡” 是各个 cpu 上具有相同数目的进程数目, 而忽略了各个进程的优先级. 但我本来设想的计算公式是:
\[w_n * {t_n \over W} * y ^ n + w_{n-1} * {t_{n-1} \over W} * y ^ {n-1} + ... + w_1 * {t_1 \over W} * y ^ 1 + w_0 * {t_0 \over W} * y ^ 0\]在我的设想中, 衰减只作用在 t 上; 但从内核当前公式上看, 衰减同时作用在 t 与 W 上, 我看不懂但我接受了这个设定.
当前内核对于每个 task_struct 维护了三类 pelt 指标, 这三类指标的区别在于 w 的值:
- load_avg, 此时若 task_struct 处于可运行/正运行的状态时, w 的值是 task_struct.se.load.weight; 若 task_struct 处于不可运行时, w = 0.
- runnable_avg, 此时若 task_struct 处于可运行/正运行的状态时, w 的值是 1; 若 task_struct 处于不可运行时, w = 0.
- util_avg, 此时若 task_struct 处于正运行的状态时, w 的值是 1; 其他情况下时, w = 0.
util_avg V.S. cpu capacity
之前另外一个困惑我的问题是内核经常把 util_avg 直接与 cpu capacity 做比较, 做运算? 为啥可以这样做? 幸运的是终于让我找到答案! 在 linux v5.0 中, util_avg 可以近似认为 = (t/W) * cpu_scale; 这里 W 为 PELT 统计时间窗口, 一般是 1024us, 其中 t 为 task 在 window 中运行时间, cpu_scale 为 cpu_capacity_orig, (t / W) * cpu_scale 确实可以认为是 task 消耗的 cpu capacity 值, 即 util_avg 是可以与 cpu capacity 做计算做比较的. 之所以这个问题困扰我很久, 是因为 linux v5.1 将 util_avg 计算改为 = (t/W) * 1024! 这样子猛一看哪能想到 util_avg 与 cpu capacity 的关系? 后来晓得了 1024 是系统中性能最高 cpu cpu_capacity_orig 的值, 也即如果 task 运行在 cpu_capacity_orig=1024 的那个 cpu 上, util_avg 是可以认为是 task 对 cpu capacity 的消耗. 但从这个公式可以看出即使是 task 运行在 cpu_capacity_orig=512 的 cpu 上, util_avg 在计算时还是使用 1024 啊! 通过找到这个改动对应的 commit 23127296889fe84b0762b191b5d041e8ba6f2599 才算明白了前因后果, 简单来说是通过在 W 统计上做了手脚. 即
The load/runnable/util_avg doesn’t directly factor frequency scaling and CPU capacity scaling. The scaling is done through the rq_clock_pelt that is used for computing those signals (see update_rq_clock_pelt())
何时更新
在何时更新 se pelt 上, 一个非常糙的算法是启动一个定时器, 每 1024us 遍历系统中所有 task struct 然后一个个更新他们的 pelt, 很明显 linux kernel 不可能这么办, 但最终效果是一样的, linux 这里手段类似于延迟计算. 在 linux kernel 中, 在每次 tick 时会更新当前正在运行的 task struct se, 此时并不会更新哪些在 runqueue 中的 task, 以及哪些不可运行的 task.
对于那些在 runqueue 中的 se, 当他们切换为正运行状态时会通过 tick 更新; 使用如下场景举个例子:
- se1 在时刻 t1 被从正运行状态切走, se1 pelt 信息刚在上一次 tick 时 t0 更新, 此时调用链 __schedule() –> pick_next_task()/pick_next_task_fair() –> put_prev_task()/put_prev_task_fair() –> put_prev_entity() –> update_load_avg(cfs_rq, prev, 0); 此时在 update_load_avg() 调用时, se1.cfs_rq.curr 仍然是 se1, 即在 update_load_avg 视角 se1 仍然是 running 状态. 此时时间窗口为 [se.avg.last_update_time=t0, now=t1], 这里 update_load_avg 调用会补齐 [t0, t1] 这段窗口内 se pelt 信息.
- 这之后 se1 不再是 running 状态, 其 pelt 一直不被更新, se.avg.last_update_time 永远停留在 t1.
- 在 t2 时刻重新调度 se1 到正运行状态, 此时调用链 __schedule() –> pick_next_task()/pick_next_task_fair() –> set_next_entity() –> update_load_avg(), 这里 update_load_avg 调用时, cfs_rq.curr 尚不是 se1, 在 update_load_avg 看来 se1 仍不是 running 状态; update_load_avg 补齐了 [t1, t2] 这段窗口内 se pelt 信息.
如果 runqueue 中的 se 被 load balance 扔到其他 cpu 上那么 pelt 何时更新? 即上面场景第 3 步换成: 在 t2 时刻 se1 被 load balance 迁移到其他 cpu. 此时调用链 detach_task() –> set_task_cpu() –> migrate_task_rq()/migrate_task_rq_fair() –> detach_entity_cfs_rq() –> update_load_avg(), 这里 update_load_avg() 会补齐 [t1, t2] 这段窗口内 se pelt 信息.
对于 blocked se, linux 采用一样的措施. 继续以上面场景为例, 如果在 t1 时刻 se1 需要 sleep, 此时 linux 会将其切走, 如上所示会在切走前做 pelt 最后一次更新, 之后便不再主动更新 se1 pelt, 直至别人调用了 try_to_wake_up(se1) 唤醒 se1, 那么此时 linux 需要为 se1 确定 dst_cpu; 其中一种可能调用链 try_to_wake_up() –> select_task_rq_fair() –> find_idlest_cpu() –> sync_entity_load_avg() –> __update_load_avg_blocked_se(), 此时会计算自 se.avg.last_update_time 之后到 cfs_rq.avg.last_update_time 期间 pelt 信息, 由于这期间 se 都是 blocked, 即然不可运行, 这里计算负载贡献时, load=runnable=running=0.
cfs_rq pelt
cfs_rq.avg 存放着 cfs_rq 粒度的 pelt 信息, cfs_rq pelt 信息等于其内所有 se, 包含正运行的, 可运行的, 不可运行的, pelt 加在一起的结果. 如文章最开始摆放的 cfs_rq 层次图: cfs_rq2.pelt = task_struct3.pelt + task_struct.pelt. 关于 cfs_rq pelt 的更新, 一种最糙的法子是每 1024us 针对每一个 cfs_rq, 计算其内所有 se pelt, 之后累加起来作为 cfs_rq pelt, 很明显 linux 不会采用这种方法, 但最终实现了一样的效果. 在每次 tick 更新 running se pelt 时, 会连带着更新 cfs_rq pelt, 此时 cfs_rq pelt 计算与 se pelt 计算公式一样, 主要在与 w 值不同:
- load_avg, w = cfs_rq.load.weight; cfs_rq.load.weight 等于所有正运行, 可运行 se.load.weight 之和. 在 se 进入 blocked 状态时, 会将自身 weight 从 cfs_rq 中移除, 即 cfs_rq.load.weight 不包含 blocked se.
- runnable_avg, w = cfs_rq.h_nr_running, h_nr_running 为所有可运行, 正运行 se 的数目.
- util_avg, w = cfs_rq.curr != NULL, cfs_rq.curr != 0 意味着当前 cpu 正运行的 se 是 cfs_rq.curr.
如下以 cfs_rq.load_avg 计算为例来演示下, 按照如上公式计算出来的 cfs_rq pelt 是怎么等于 cfs_rq 各个 se pelt 之和的,
-
在时刻 t0, cfsrq1 中有三个 se se1, se2, se3, se1 正运行, se2, se3 可运行. 此时在 tick 中计算 cfsrq1 pelt, 这里 contrib 见 accumulate_sum(), divider 见 ___update_load_avg():
\[cfsrq1.pelt.t0 = cfsrq1.weight * {contrib \over divider } \\= (se1.w + se2.w + se3.w) * {contrib \over divider } \\= (se1.w * {contrib \over divider }) + (se2.w * {contrib \over divider }) + (se3.w * {contrib \over divider }) \\=se1.pelt.t0 + se2.pelt.t0 + se.pelt.t0\] -
在时刻 t1, se1 sleep, 切换到 se2 运行, 此时在 tick 中计算 cfsrq1 pelt:
\[cfsrq1.pelt.t1 = cfsrq1.pelt.t0 * y ^ 1 + cfsrq1.weight * {contrib \over divider } \\=cfsrq1.pelt.t0 * y ^ 1 + (se2.w + se3.w) * {contrib \over divider } \\=se1.pelt.t0 * y ^ 1 \\+ se2.pelt.t0 * y ^ 1 + se2.pelt.t1 \\+ se3.pelt.t0 * y ^ 1 + se3.pelt.t1\]由于 se1 blocked, 即 se1.pelt.t1 被认为是 0, 但 se1.pelt.t0 仍然在 cfsrq1.pelt 中, 一起被衰减了. 这也是 pelt 主张的: blocked se 仍然是有负载贡献的.
group se pelt
group se pelt 等于其 my_q 的 pelt 信息, 即: se2.pelt = se2.my_q.pelt. task_group.pelt = 其内所有 cfs_rq pelt 之和. 另外 group se weight = task_group.shares * (gse.load_avg / tg.load_avg). 这些设定看起来还是很合理的. group se, task group pelt, group se weight 都是在 tick 更新 running se pelt 时自底向上完成更新. 如下以 task_struct3 迁入当前 cpu 执行场景为例, 此时与 pelt 相关链路:
- enqueue_task_fair(rq, p);
- enqueue_entity(cfs_rq2, se3);
- update_load_avg(cfs_rq2, se3);
- 此时 se3 是迁入, 其 last_update_time 为 0, attach_entity_load_avg(cfs_rq2, se3)
- add_tg_cfs_propagate(cfs_rq2, se3.avg.load_sum)
- cfs_rq2.propagate = 1;
- cfs_rq2.prop_runnable_sum = se3.avg.load_sum
- add_tg_cfs_propagate(cfs_rq2, se3.avg.load_sum)
- update_tg_load_avg(cfs_rq2);
- 此时 se3 是迁入, 其 last_update_time 为 0, attach_entity_load_avg(cfs_rq2, se3)
- update_load_avg(cfs_rq2, se3);
- enqueue_entity(cfs_rq1, se2);
- update_load_avg(cfs_rq1, se2)
- propagate_entity_load_avg(se2), 此时 gcfs_rq=cfs_rq2, cfs_rq=cfs_rq1,
- add_tg_cfs_propagate(cfs_rq1, cfs_rq2.prop_runnable_sum)
- cfs_rq1.propagate = 1; cfs_rq1.prop_runnable_sum = cfs_rq2.prop_runnable_sum.
- update_tg_cfs_util(cfs_rq1, se2, cfs_rq2);
- update_tg_cfs_runnable(cfs_rq1, se2, cfs_rq2)
- update_tg_cfs_load(cfs_rq1, se2, cfs_rq2);
- add_tg_cfs_propagate(cfs_rq1, cfs_rq2.prop_runnable_sum)
- update_tg_load_avg(cfs_rq1)
- propagate_entity_load_avg(se2), 此时 gcfs_rq=cfs_rq2, cfs_rq=cfs_rq1,
- update_load_avg(cfs_rq1, se2)
- enqueue_entity(cfs_rq0, se1)
- update_load_avg(cfs_rq0, se1)
- propagate_entity_load_avg(se1), 此时 gcfs_rq=cfs_rq1, cfs_rq=cfs_rq0,
- add_tg_cfs_propagate(cfs_rq0, cfs_rq1.prop_runnable_sum); cfs_rq0.propagate = 1, cfs_rq0.prop_runnable_sum = cfs_rq1.prop_runnable_sum
- update_tg_cfs_util(cfs_rq0, se1, cfs_rq1);
- update_tg_cfs_runnable(cfs_rq0, se1, cfs_rq1)
- update_tg_cfs_load(cfs_rq0, se1, cfs_rq1);
- update_tg_load_avg(cfs_rq0), cfs_rq0 属于 root_task_group,
- propagate_entity_load_avg(se1), 此时 gcfs_rq=cfs_rq1, cfs_rq=cfs_rq0,
- update_load_avg(cfs_rq0, se1)
- enqueue_entity(cfs_rq2, se3);
关于这块其实还想再写一点, 可是我要去吃团队年夜饭了==
后语
入门了 linux 调度之后, 真的有种醍醐灌顶的清明感啊!