在去年 9 月份做了 PaperReading: Nanoflow 分享之后, 随着 Deepseek TBO 的流行, 我也陆续收到不少关于 Nanoflow 算子如何重叠执行的追问, 一直想找时间详细绘制下 nanoflow 具体地执行流, 现在时间来啦!
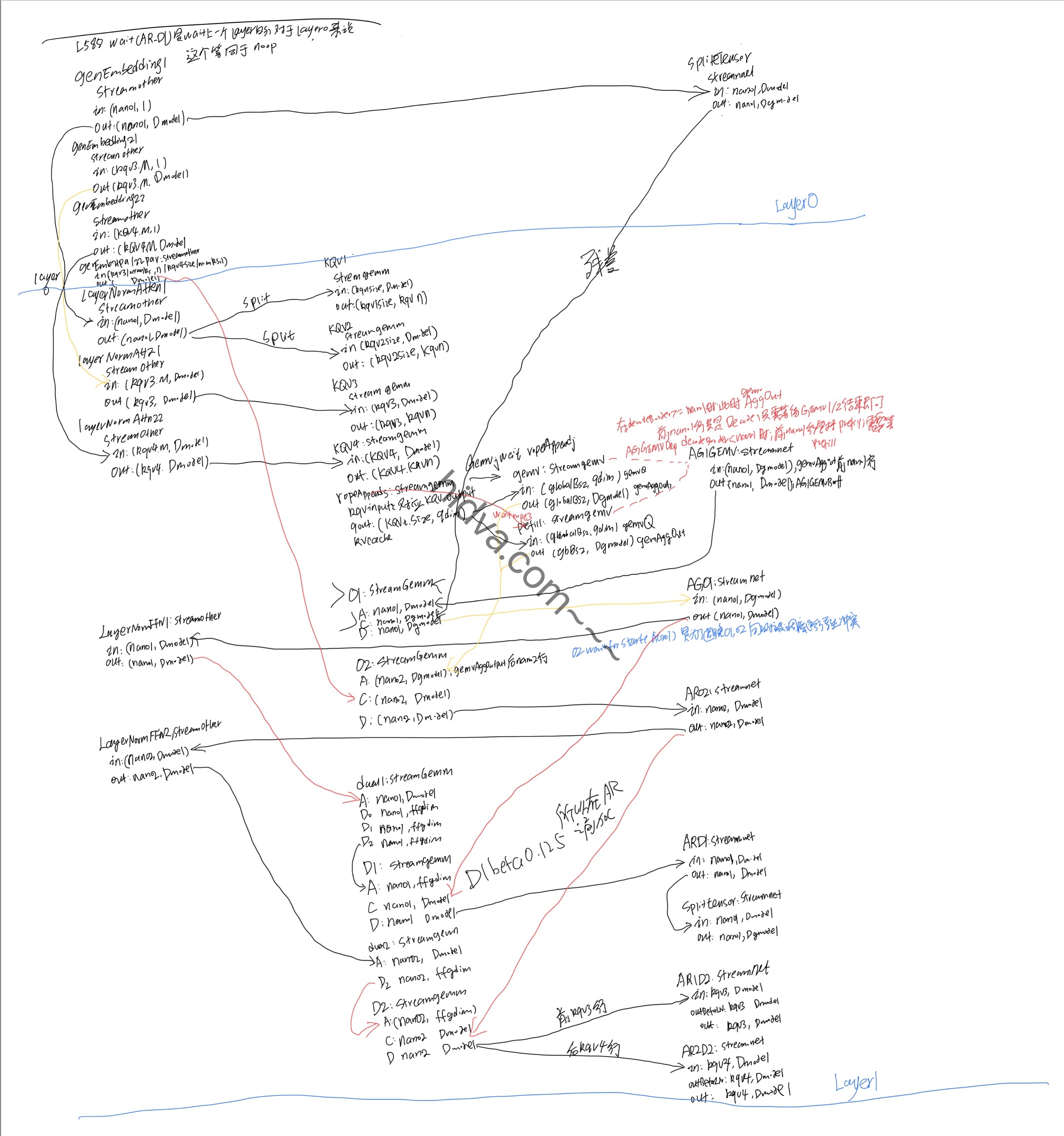
我本来想着将上面草图转换为 graphviz 形式, 但感觉好麻烦啊= 关键是上面草图信息已经够直观了, 应该没必要了=
Q1: 在 AG_O1 -> D1 -> AR_D1 执行流中, 这里 AG_O1 结果作为 GEMM D1 矩阵 C 的角色(即残差), 之后再进行 AR_D1, sum 结果不对吧. 不应该就像论文中 Figure 1 一样先 AR 之后才加上 AG_O1 的结果(即残差) 么?
A1: GEMM D1 beta=0.125, 即 D1 计算的是 A * B + 0.125 C, 也即每个 rank 在计算残差时使用的系数是 0.125, 8 个 rank AR 之后, 等同于先 AR 再残差了.
Q2: 那我问你, 为啥在 O2 -> AR_O2 这条执行流中, O2 的 beta 系数是 1?
A2: 这是因为 O2 用作残差的矩阵 C 只有部分是有数据的, 其余部分是 0. 举个栗子:
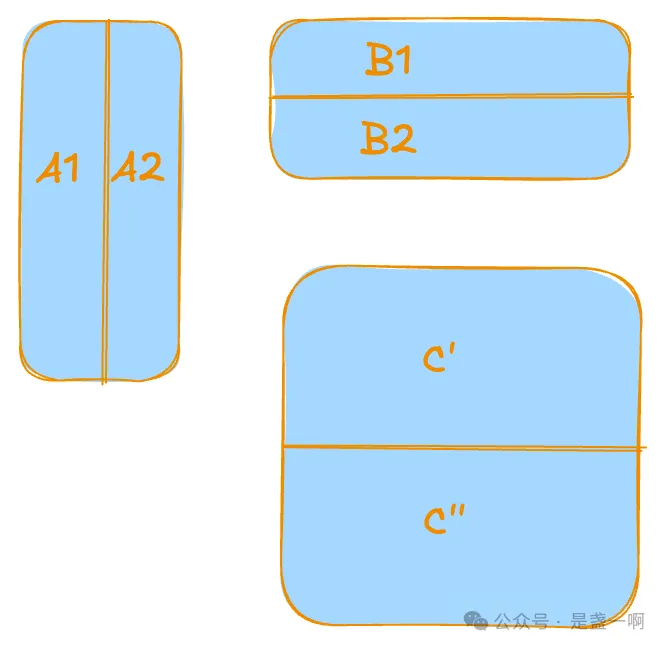
现在我们分两个 rank 计算 A * B + C, 令 $C_1 = \begin{pmatrix} C’ \\ 0 \end{pmatrix} C_2 = \begin{pmatrix} 0 \\ C’’ \end{pmatrix}$
那么 A * B + C = AR(A1 * B1 + C1, A2 * B2 + C2).
O2 矩阵 C 是 AR12_before, 其值有两个来源, 这俩来源都符合 C1, C2 的特征, 即只有部分是有数据的, 其余部分是 0.
-
genEmbedding2_1_partial, genEmbedding2_2_partial 的输出, 这俩输出存放在
AR12_before.subtensor(rank * (AR12_before.rows/vnranks), AR12_before.rows/vnranks), 即是 O2.C 一部分. B.T.W 我本来以为这俩算子没用呢, 毕竟没有 kernel wait 这俩. -
AR1_D2.output_before_ln, AR2_D2.output_before_ln. 如下实现所示, 可以看到 output_before_ln 只经历了 AR reduceScatterKernel 阶段, 即其也是只有部分有数据, 其余部分是 0.
reduceScatterKernel(sm_input_buff_channels, global_syncer, rank, nranks, nelem_per_shard, input, output_before_ln);
__syncthreads();
auto local_output_shards_before_ln = output_before_ln + local_offset;
auto local_output_shards_of_ln = output + local_offset;
rmsnorm_device<half, half2>((float4 *)local_output_shards_of_ln, (float4 *)local_output_shards_before_ln,
(float4 *)ln_weight, rows, columns, epsilon);
__syncthreads();
allgatherKernel(sm_output_buff_channels, syncers, nchannels, local_offset, nelem_per_shard, output, output);