本篇文章是之前学习 vllm 源码时纪录的笔记, 参考着 vllm 0.6.2 的代码做了更新. 顺便略作整理之后发了出来, 希望能帮忙您=. =
llm 中的 sampler 本身要做的事情还是比较直观的, 就是根据模型输出的 next token 的 logits 按照指定的策略选择 next token id. 这里介绍下 vllm sampling 模块的主要数据结构与实现. 首先看下 vllm 中模型输出 tensor 形状 model_output:

如图所示, 此时 seq group sg1, sg2, sg3 均处于 prefill 阶段. 对于 sg1 而言, 其有 4 个 input prompt token 参与本次 step; do_sample=1 意味着本次 step 需要为 sg1 预测第一个 output token, 即 sg1 所有未处理的 input prompt token 都将在本次 step 中得到处理. sg2 有 3 个 input prompt token; sg3 有 5 个 input prompt token. seq group sg4 处于 decode 阶段, 其内有两个 sequence 参与本次 step. sg4.s1 那一行存放着模型为该 sequence 预测的下一个 token 的 logits, sampler 就是根据这行信息为 sequence sg4.s1 选择 next token id.
理论上 sg1, sg2, sg3 都处于 prefill 阶段, 其不应该参与到 sampling 中逻辑来的, 但 vllm 支持 prompt_logprobs 功能. prompt_logprobs 与 openai logprobs 功能类似, 其会为除第 1 个 prompt token 之外的所有 prompt token 输出模型预测的概率, 以及指定数目的候选 token id 及对应的 logprobs. 所以 sampling 也会处理 sg1/sg2/sg3.
sampling 的第一步是生成 SamplingMetadata:
# seq_group_metadata_list, 参与本次 step 的 seq group. 处于 prefill 阶段的 seq group 位于 decode seq group 之前.
# seq_lens 与 seq_group_metadata_list 一一对应, 存放着本次迭代能看到的 token 数目.
# query_lens 与 seq_group_metadata_list 一一对应, 存放着 seq group 参与本次 step 的 token 个数.
SamplingMetadata.prepare(
seq_group_metadata_list:List[SequenceGroupMetadata],
seq_lens: List[int],
query_lens: Optional[List[int]],)
映入眼帘的便是 _prepare_seq_groups(seq_group_metadata_list, seq_lens, query_lens), 这里 selected_token_indices 存放着 model_output 中需要被 sampling 模块处理的行的下标集合, model_output 经 selected_token_indices 过滤之后得到 sampling_input. 以 sg3 未开启 prompt_logprobs, sg1/sg2 对应请求用户指定了 prompt_logprobs 为例, 此时 selected_token_indices = [0, 1, 2, 3, 4, 5, 6, 11, 12, 13].

这里 model_output 的 [7, 8, 9, 10] 等行会被直接丢弃掉. 话说既然要被直接丢弃掉, 是不是连算都省了, 注意这种省只能作用在最后一个 layer.
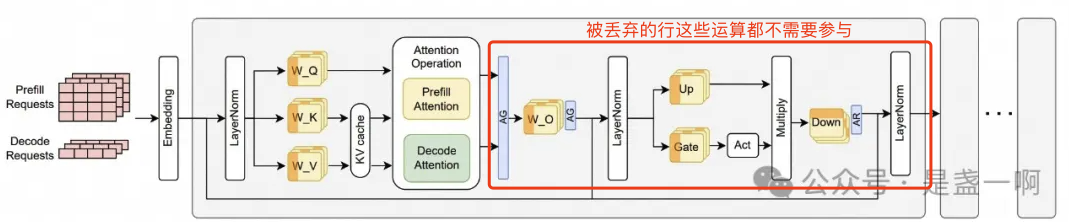
可能是太鸡肋了吧, 以 qwen2 为例其有 80 个 layer, 前 79 个 layer 中这些运算都是不能被省掉的.
prompt_logprob_len, sample_len; 如上可以看到每个 seq group 在 model_output 都对应着若干行, sample_len 为 seq group 在 model_output 中对应 output token 的行的个数, prompt_logprob_len 为对应 input prompt token 行的个数. 以 sg1 为例, 其在 model_output 中有 3 行 t1,t2,t3 对应着 input prompt token, 1 行 t4 对应着 output token. 这里 “对应” 怎么理解? 以 t1 行为例, 其对应着模型预测的 t1 下一个 token 的信息, 即对应着 input prompt token 的 t2. 以 t4 行为例, 其为模型预测的 t4 下一个 token, 这里不对应着任何 input prompt token, 而是对应着 output token. 很明显对于 prefill seq group 来说 sample_len + prompt_logprob_len = query_len. 对于 decode seq group 来说 prompt_logprob_len = 0.
model_output_idx, logit_idx, 如上可知在 model_output/sampling_input 中, 每个 seq group 都对应着一组行, model_output_idx 为 seq group 首行在 model_output 的下标, logit_idx 为 seq group 首行在 sampling_input 中的下标.
for i, seq_group_metadata in enumerate(seq_group_metadata_list):
# model_output_idx 此时为当前 seq group 在 model_output 的起始下标.
# 对于 sg1 而言, model_output_idx = 0. logit_idx = 0
# sg2 对应 model_output_idx = 4. logit_idx = 4
# sg3 对应 model_output_idx = 7. logit_idx = 7
# sg4 对应 model_output_idx = 12. logit_idx = 8
seq_ids = seq_group_metadata.seq_data.keys()
prompt_logprob_indices, sample_indices; prompt_logprob_indices 为 seq group 在 sampling_input 中对应 input prompt token 行的下标集合. sample_indices 为对应 output token 行下标集合. 以 sg1 为例 prompt_logprob_indices = [0, 1, 2], sample_indices = [3]. 以 sg2 为例 prompt_logprob_indices = [4, 5, 6], sample_indices = []. 以 sg3 为例 prompt_logprob_indices = [], sample_indices = [7].
sample_idx; 如上所述, sampling_input 中即包含 input prompt token, 也包含着 output token. 我们将所有对应着 input prompt token 的行都移除掉进一步得到 sampling_input_only_sample:
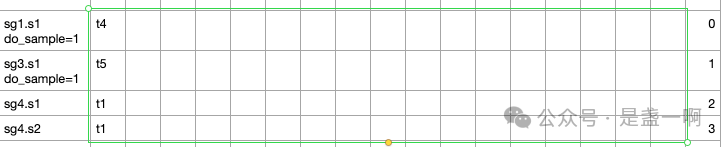
此时对于每个 seq group, sample_idx 为该 seq group 在 sampling_input_only_sample 的起始下标. 比如 sg1 对应 sample_idx = 0, sg2 对应 sample_idx = 1, sg3 对应 sample_idx = 1; sg4 对应 sample_idx = 2.
categorized_sample_indices[sample_type]; 一个 seq group 对应着一个用户请求, 不同请求可能具有不同的 sample type. categorized_sample_indices[sample_type_1] 存放着所有 sample_type=sample_type_1 的 seq group 的 output token 对应 logit_idx, sample_idx.
categorized_sample_indices[sample_type_1] = [
(sg1.output_token1.logit_idx, sg1.output_token1.sample_idx),
(sg3.output_token1.logit_idx, sg3.output_token1.sample_idx),
# 对应着 sequence sg4.s1
(sg4.output_token1.logit_idx, sg4.output_token1.sample_idx),
# 一个 sequence 对应着一个 output token.
(sg4.output_token2.logit_idx, sg4.output_token2.sample_idx),
]
P.S. vllm 0.6.2 移除了 sample_idx!
在搞懂了 SamplingMetadata 结构之后, 真正的采样实现就比较直观了, 以 qwen2 为例, 直接看 Qwen2ForCausalLM.sample(logits, sampling_metadata) 即可, 这里 logits 对应着我们上面所说 sampling_input, P.S. 不是 model_output.
值得一提的是 _apply_top_k_top_p resort 实现, 本来很简单的就是 logits[s][logits_idx[s][t]] = logits_sort[s][t], 但 vllm 实现一开始绕了一圈让我迷了会..
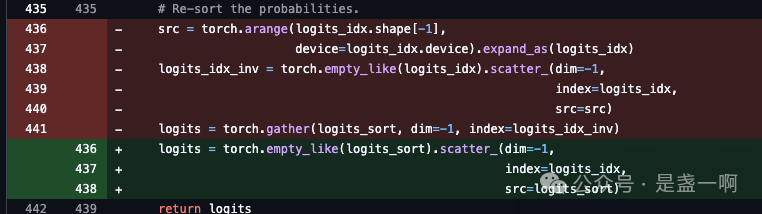
所以水了个 PR.