整理笔记时发现这篇之前学习 transformer 的总结, 略加梳理之后发表出来, 希望能帮到你=. = 本文假设你已经有 这里 提到的数学常识.
先看 transformer, 先理清 encoder 一个层输入/输出, 如下图所示, P.S. 我发现动动手把输入/输出 shape 写出来很是有助于加深理解呀.:
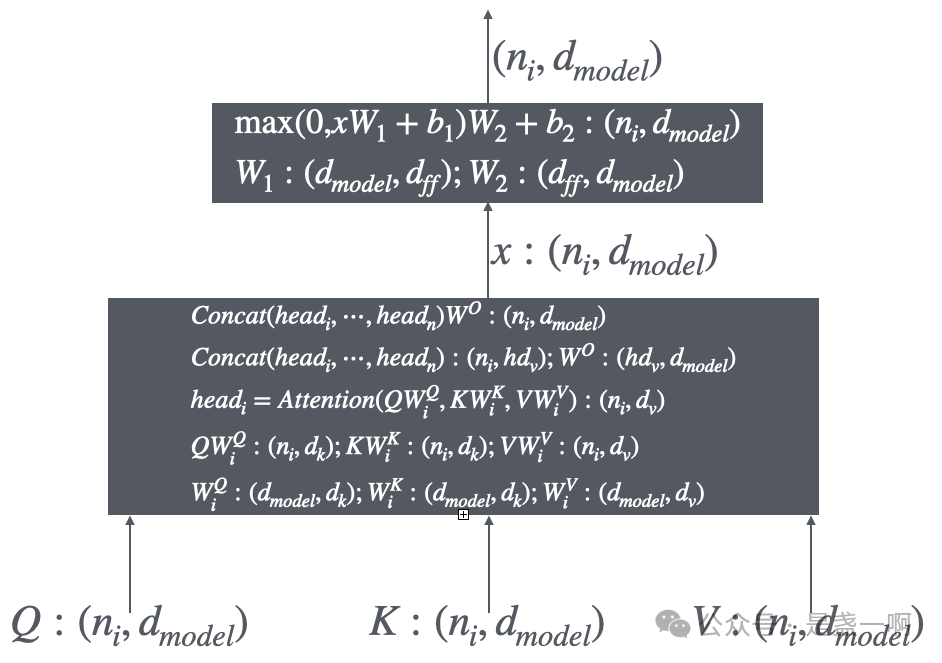
encoder 部分最低层的输入很明显是用户输入, 此时 $n_i$ 即用户输入 token 个数, 每个 token 使用一个 $d_{model}$ 维向量编码; 即 $Q: (n_i, d_{model})$ 每一行对应着用户输入的一个 token. encoder 中间层的输入 $Q, K, V$ 是一致的, 均是其下一层的输出. encoder 最顶层的输出将作为 decode 模块的输入. 之后再看 decode 部分其中一层输入/输出, 如下图所示:
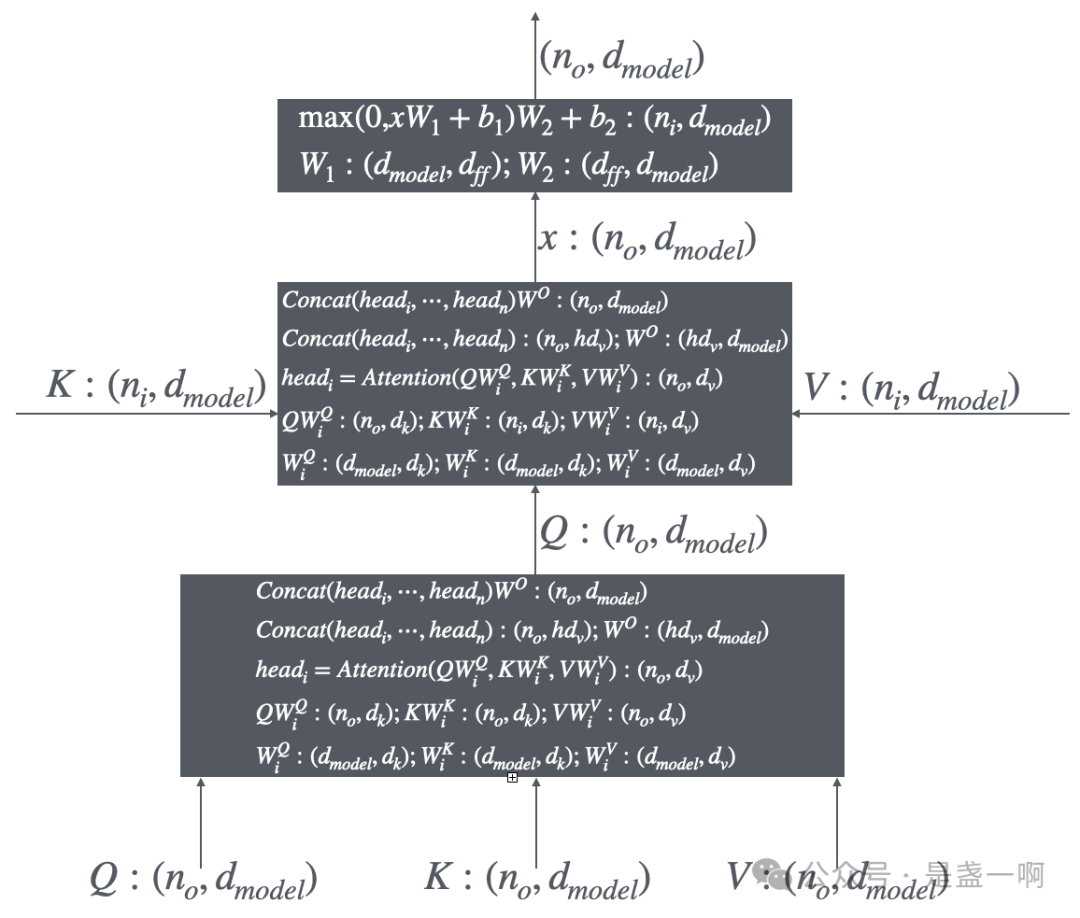
此时 $n_o$ 为 decoder 部分输入 token 的个数, 注意与 $n_i$ 区分开来; decoder 中间层的输入就是其低层的输出. 关于最低层的输入, 最顶层的输出, 我们这里使用个具体场景来解释. 假设现在 encoder 部分完成了用户输入的处理, 我们来模拟下此时 decoder 部分运行情况:
- 首先给 decoder 最低层一开始标记
<SOS>, 此时 $n_o = 1$; 经过一轮完整了的 decoder 得到输出 $O_1 = (1, d_{model})$, 经过 softmax 得到了一个 token t1. - 给 decoer 最低层输入
<SOS>, t1, 此时 $n_o = 2$; 经过一轮完整了的 decoder 得到输出 $O_2 = (2, d_{model})$. 此时第一行对应于基于<SOS>预测的下一个 token, 这里第一行内容与 token t1 对应的 $(1, d_{model})$ 很相近. 第二行对应于基于<SOS>, t1预测的下一个 token. 此时将第二行传递给 softmax 得到了一个 token t2. 这个也是我一开始的疑问, 和 这里 老哥一样的疑问: 应该使用输出 $(2, d_{model})$ 的哪一行作为 linear + softmax 的输入. - 再给 decoder 最低层输入
<SOS>, t1, t2, 此时 $n_o = 3$; 得到输出 $O_3 = (3, d_{model})$.
实际上, 我们现在还一直忽略 decode 部分 Masked Multi-Head Attention 组件; 如果我们不考虑 masked 的存在, 实际上我们 decoder 那张图就没有绘制 masked, 这里以上述步骤第 3 步为例, 我们走一下上面 decoder 那张图. 可以发现此时输出的 $O_3 = (3, d_{model})$, 其第一行本来语义是基于 <SOS> 预测的下一个 token. 但由于没有 masked 的存在, 我们的 decoder 在输出这一行时是参杂着 <SOS> 与 t1, t2 的注意力的! 这导致 $O_3$ 的第一行, $O_2$ 的第一行, 与 $O_1$ 不再相似, 虽然他们仨语义上都是基于 <SOS> 预测的下一个 token. 我个人对此到没感觉没啥不好, 但 transformer 论文认为这有伤因果, 所以加了 masked. 可能是如果真的没有 mask, 那么 kvcache 这类优化技术完全用不了, 推理速度将无法接受吧=. =
知道了 masked 要解决的问题, 那么其实现接下来就很清晰了, 可以参考 The Annotated Transformer 理解下. 太晚了, 我这里就不赘述了.
再回到 GPT, 实际上我一开始以为 GPT 与 transformer 是一回事= 这倒是我在读 chunked prefill 这些论文时很是莫名其妙, 因为在 transformer 中 encoder 是没有 masked 的, 输入中一个 token 要考虑其后 token 注意力的, 那么 chunked prefill 根本用不了呀. 后来才发现 GPT 与 transformer 相似但不是一回事, 主要区别在于: GPT 只有 decoder 部分, 且其 decoder 一个层只有 Masked Multi-head Attention + FeedForward 组成. 用户输入将作为 decoder 最底层的输入. 所以 GPT 是对用户输入也应用 masked 的, 即用户输入中一个 token 仅考虑在其之前的 token. 那这样的话, GPT 是不是对倒装句不是很友好呀? 嘿! 睡觉了我要!