在写完 C++ memory order: load(SeqCst) VS fetch_add(0, SeqCst) 这篇文章之后, 随着知识的进一步积累的, 一种不踏实感油然而生, 尤其是在收到一封感谢邮件之后:
I notice that you have an interesting blog post regarding why fetch_add(0) is used rather than load(). It was not me who fixed that bug in Tokio, and I did not actually know why the fetch_add(0) is necessary, so thanks for explaining.
让我不踏实的原因是我后来了解到 C++ 标准规定, 所有 SeqCst action, 包括 memory read/write/fence, 形成一个 total order:
Atomic operations tagged memory_order_seq_cst not only order memory the same way as release/acquire ordering (everything that happened-before a store in one thread becomes a visible side effect in the thread that did a load), but also establish a single total modification order of all atomic operations that are so tagged.
即我之前文章中描述的行为是不可能发生的,
thread1 thread2
1. cell.fetch_sub(1, SeqCst), 退出 search 状态, 此后 cell = 0
2. 在检查一次有没有 task 要干, 没有则 go to sleep.
1. 创建一个 task 扔到执行队列中.
1. cell.load(0, SeqCst), 看到的 cell 仍然是 1!
所以认为 thread2 还没有执行 fetch_sub 退出
search 状态, 认为第 1 步创建的 task 能被
thread2.2 看到,
如果在 seq_cst total order 中 thread1 的 cell.load(0, SeqCst) 在 cell.fetch_sub(1, SeqCst) 之后, 那么 cell.load() 是一定能看到 fetch_sub(1) 之后的值的. 不幸的是, 当时的我也不会其他解释了…
但现在我手握 x86 memory model, arm/power memory model, CPP memory model 形式化验证工具, 是时候再次对这个问题发起总攻了! 如下是问题出现时, 涉及到的线程, 以及他们的 atomic memory 操作顺序以及操作结果:
main thread, 负责创建提交 task, 并在必要的时候唤醒 worker 来执行新 task,:
- self.len.store(len + 2, Release); 将 task 放入队列, 更新队列中长度.
- let state = State::load(&self.state, SeqCst); state 中存放着当前有多少 worker 处于运行状态, 多少个 worker 处于搜索任务状态. 在 issue 场景中, 这里 state 的值: searching: 1, unparked: 1, num_workers: 2. 即总共有 2 个 worker, 其中 1 个 worker0 处于 parked, 睡眠状态. 另一个 worker1 处于 searching, 搜寻任务状态. 此时 main thread 认为这个处于 searching 状态的 worker1 会发现并执行 new task, 因此 main thread 决定不唤醒 pakred worker0.
worker1, 负责执行 task, 并在没有 task 时睡眠.
- transition_to_parked() –> transition_worker_to_parked(idx, is_searching=true); –> let prev = State(self.state.fetch_sub(dec, SeqCst)); 在 issue 场景中, worker1 刚刚结束 searching task 过程, 并且发现没有任务, 准备睡眠. worker1 通过 atomic RMW 将 state 从 (searching=1, unparked=1, parked=1) 更新为 (searching=0, unparked=0, parked=2).
- self.owned().work_queue.is_empty() –> self.len.load(Acquire); worker1 在睡眠之前再做最后一次检测, 看看队列中是否有新 task. 在 issue 这个场景中, len.load(Acquire) 返回了 0, worker1 认为没有新任务, 睡了.
如上过程可以编写为等价的 CPP memory model test program:
int main() {
// x 即 task queue len.
atomic_int x = 0;
// y 即 state.
atomic_int y = 1;
{ { {
// main thread
{
x.store(1, memory_order_release);
y.load(memory_order_seq_cst).readsvalue(1);
}
|||
// worker1
{
y.store(0, memory_order_seq_cst);
// worker1 看到 queue len = 0.
x.load(memory_order_acquire).readsvalue(0);
}
} } }
return 0;
}
并在 CppMem: Interactive C/C++ memory model 进行验证, 可以得到 issue 场景中对应的执行模式, 这个执行模式是符合 CPP 标准定义的 memory model 的:
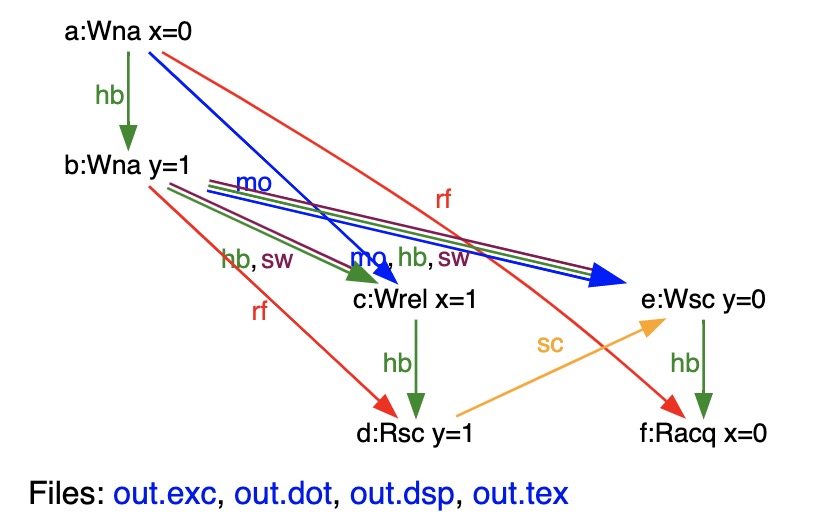
图中, “sc” 标注的 d –> e 边, 意味着在 seq_cst total order 中, d 位于 e 之前; 可以看到这里 sc 并不会影响 happen before, hb 关系.
如上代码在 x86 平台的编译结果:
// main thread
// self.len.store(len + 2, Release); 翻译为纯粹的 mov.
mov [self.len], len + 2
// State::load(&self.state, SeqCst)
mov rax, [self.state]
// worker1
// self.state.fetch_sub(dec, SeqCst)
lock sub [self.state], dec
// self.len.load(Acquire)
mov rax, [self.len]
结合 x86 TSO memory model:

Here each hardware thread has a FIFO write buffer of pending memory writes. Moreover, a read in TSO is required to read from the most recent write to the same address, if there is one, in the local store buffer.
A program that writes one location x then reads another location y might execute by adding the write to x to the thread’s buffer, then reading y from memory, before finally making the write to x visible to other threads by flushing it from the buffer. In this case the thread reads the value of y that was in the memory before the new write of x hits memory.
在 issue 这个场景中, main thread 对 self.len 的写入仍然在 main thread 所在 CPU local write buffer 中, 对其他线程都不可见的. worker1 对 self.len 读取来自于 shared memory, 仍然是 main thread 更新前的值, 即 0.
为啥把 load(SeqCst) 换乘 fetch_add(0, SeqCst) 就可以?! 从 C++ memory model 解释是:
A load operation with this memory order performs an acquire operation, a store performs a release operation, and read-modify-write performs both an acquire operation and a release operation, plus a single total order exists in which all threads observe all modifications in the same order
之前 main thread 执行的 load(SeqCst) 仅是一个 acquire operation, 并不会与 worker1 任何操作形成 synchronizes-with 关系. 改成 fetch_add(0, SeqCst) 之后同时是一个 Acquire/Release operation, 与 worker1 的 self.state.fetch_sub(dec, SeqCst) 这个 Acquire/Release operation 形成了 synchronizes-with 关系, 使得 main thread fetch_add(0) 之前的所有副作用对 worker1 可见.
从 x86 编译后的结果, 这里 mfence 会 flush 当前 cpu write buffer 中的内容到 shared memory.
// fetch_add(0, SeqCst)
mfence
mov rax, qword ptr [rdi]
即 main thread 这个 mfence 使得 main thread 之前对 self.len 的改动从 write buffer 刷新到 shared memory, 便对 worker1 的 load(Acquire) 可见了.