即上一篇 关于 Spanner 的若干猜测 之后, 继续跟进了 Spanner 另一篇论文 “Spanner: Becoming a SQL System”, 同样这篇文章不是论文介绍文章, 而是对论文一些我感觉模糊的地方所做的猜测. 非常欢迎/希望一起交流一下.
3.1 Distributed query compilation
Spanner 中 SQL 优化过程, 当 Spanner 收到一条查询时:
- 按照单机 PG 那样生成 plan tree,
-
A Distributed Union operator is inserted immediately above every Spanner table in the relational algebra. 从下面这段描述:
Spanner does that using well-known multi-stage processing – partial local Top or local aggregation are pushed to table shards below Distributed Union while results from shards are further merged or grouped on the machine executing the Distributed Union.
能看到 DU 等同于 Greenplum 中的 Gather Motion, 是个 N:1 模型, 其只能有 1 个消费者.
- 按照 3.1 章节中的规则, 尽量将 DU operator 往上提, 以及合并 DU operator.
When Distributed Union is being pulled up through Filter operators, it collects filter expressions involving sharding keys. 在 Figure 1 中, DU 的 sharding key filter expression 就是 c.ckey IN UNNEST(@array...).
we do not rely on static partitioning during query planning. 与之相对的比如 Greenplum, 其在 plan 期间就会利用数据分布的特征进行裁剪, 在 Greenplum 中, 如果一个表 table1 按照列 i 进行 hash 分布, 那么 select * from table1 where i = 33 在 plan 期间 GP 就确认了这条 SQL 只会发往一个特定的 segment. 如下所示:
explain (costs off) select * from table1 where i = 33;
Gather Motion 1:1 (slice1; segments: 1) # 这里 Motion 只会下发到 1 个节点.
-> Seq Scan on table1
Filter: (i = 33)
Optimizer: Postgres query optimizer
explain (costs off) select * from table1 where j = 33;
Gather Motion 3:1 (slice1; segments: 3) # j 不是分布列, 所以会下发到集群中全部 3 个节点中.
-> Seq Scan on table1
Filter: (j = 33)
Optimizer: Pivotal Optimizer (GPORCA)
但在 Spanner 中, DU 算子将总会生成, 在运行时会结合 DU 算子中的 sharding key filter expression 以及当时的 table key space 分布确认需要发往哪些 shard.
3.2 Distributed Execution
Spanner can push more complex operations such as grouping and sorting to be executed close to the data when the sharding columns are a proper subset of grouping or sorting columns. 从这个描述可以看出,spanner 按照 column col 切分 shard 时, shard 之间完全不相交的, 即如果表 t 按照 col1, col2 进行 range 切分, 那么具有相同 col1 值的行总是位于一个 shard 中. 这个前提也是下面 local join 的基础.
On large shards, query processing may be further parallelized between subshards. For that, Spanner’s storage layer maintains a list of evenly distributed split points for choosing such subshards. 我理解这里 subshards 之间应该也互不相交, 即不会有一个 key prefix 同时存在两个 subshards 之间.
3.3 Distributed joins
Figure2 中的 map, 与 CrossApply(input, map) 中的 map 性质相同, 这个 map 输入是一行, 输出是一行或多行; 具体可以以 Figure1 中 CrossApply 的 map 为例, 这个 map 接受 Customer c 吐出的一行 row, 会输出与 Sales 表中与 row 匹配的行, 可能的输出姿势类似于:
# Customer 中 row1 对应着 Sales 中 3 行.
<Customer.row1, Sales.row1>
<Customer.row1, Sales.row2>
<Customer.row1, Sales.row3>
# Customer 中 row2 对应着 Sales 中 2 行.
<Customer.row2, Sales.row4>
<Customer.row2, Sales.row5>
Figure2 描述了 3.3 的核心, 可以认为 DistributedApply 是 DistributedUnion 的子类, 其具有 DU 的所有特性, 比如 DA 也有 sharding key filter expression. DA 的执行模型伪代码描述:
while 1:
batch = get_batch_from_left_side()
if not batch:
# 如果 batch 为空, 即没有数据了, 则返回.
break
# 根据 batch 以及 sharding key filter expression 计算出 shard_batch, 这里 shard_batch 结构:
# <shard1, batch1>, <shard2, batch2>, ..., <shardN, batchN>.
# 其中 batch1 + batch2 + ... + batchN = batch.
# 意味着本次 DA 需要将 <subquery, batch1> 下发给 shard1, <subquery, batch2> 下发给 shard2, ...
# shard1 会执行 subquery, 使用 batch1 作为输入, 吐出结果.
# DA 会合并所有 shard 吐出的结果
# calc_batch 实现了 'Distributed Apply performs shard pruning using the following steps' .
# batch1, batch2 即对应着 step4 中的 minimal batch.
shard_batch = calc_batch(batch)
result = parallel_dispatch(shard_batch)
Locally on each shard, seek range extraction takes care of scanning a minimal amount of data from the shard to answer the query.
4. QUERY RANGE EXTRACTION
本来这一章, 我是稀里糊涂的, 不清楚 filter tree, self-joins, range extraction 在一次查询中是如何串起来的. 现在有点明白了. 我理解是如果过滤条件不是很复杂, 可以被 correlated self-joins 实现, 比如 Figure 3 中提到的表达式, 那么此时就没有 filter tree 的必要了, 只需要一个 correlated self-joins tree 即可.
但如果过滤条件比较复杂, 比如包含 ‘OR’ 等, 像 Figure 4 中的表达式, 那么就需要以此表达式构造一个 Filter tree, 之后根据 PK column 的数量 N 构建一个具有 N + 1 Scan 节点的 correlated self-join tree, 如下图所示:
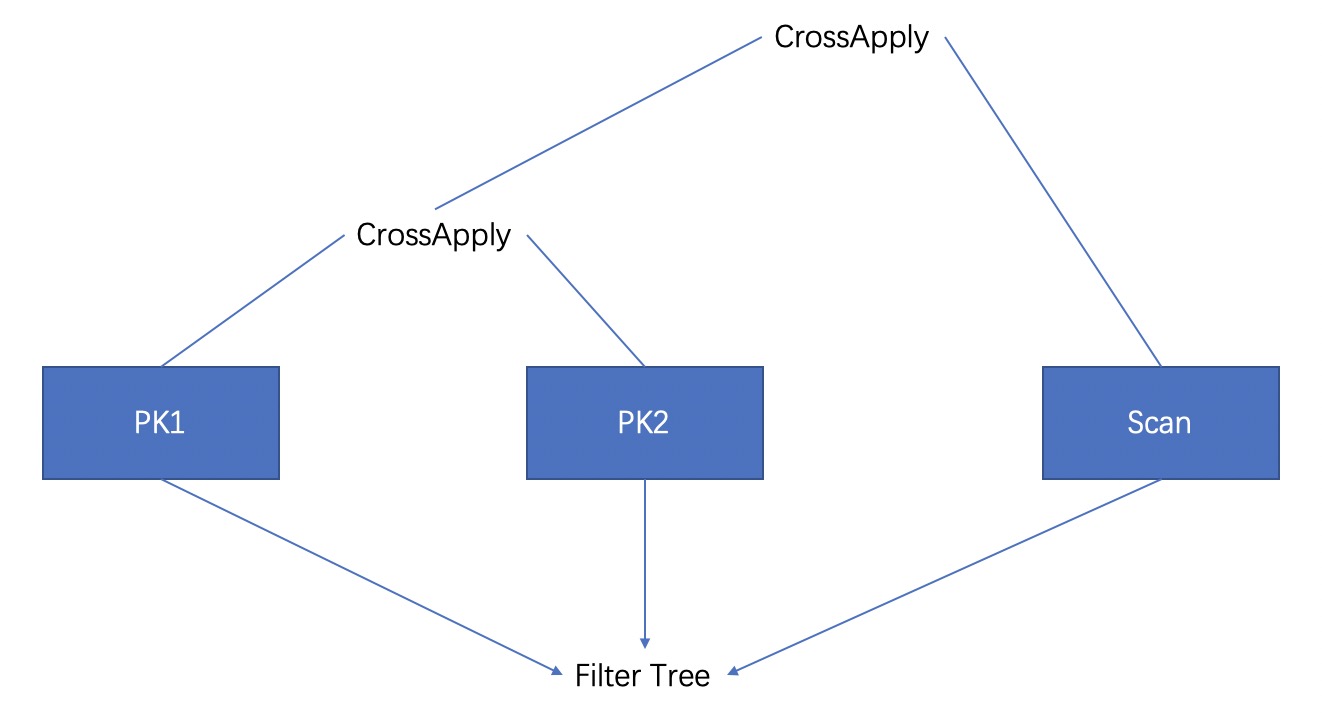
correlated self-joins tree, 可以认为就是最终执行的物理计划, 我理解 self-join tree 中的 Scan 节点数目等于 PK column 的数目 + 1, 每一个 Scan 负责吐出其对应 PK col 的范围, 最后一个 Scan 负责扫描所有满足条件的行, 并按照用户表达式进行过滤, 吐出结果. 以上图 filter-tree 为例 correlated self-joins tree 执行姿势大概是:
- 首先运行 PK column1 对应的 Scan, 此时该 Scan 会自底向上扫描 filter tree, 根据 filter tree 收集 column 1 的 range, 之后吐给下一个 Scan.
- 再运行 PK column2 对应的 Scan, 其接受 PK column1 吐出的关于 column1 range 的结果, 在此基础上继续自底向上遍历 filter tree, 收集 column2 的 range, 继续吐出.
- 最后运行最后一个 Scan 节点, 其根据 column1, column2 的 range Seek 扫描所有行, 带入 filter tree 求值, 吐出满足条件的行,
我明白了么?
5. QUERY RESTARTS
Streaming pagination through query results, 类似于 PG PBE extended protocol 啊, 用户可以多次发送 E message, 每次指定 E message 吐出的最大数量.
这一章很多关键的信息没有说: We defer them to a separate paper! 如下是总结出来的有效信息:
restart token, 参见 ‘To support restarts Spanner extended its RPC mechanism with an additional parameter’ 段了解, 就很好奇是如何实现的?
distributed state, Therefore, we implemented SQL query restarts inside the query processor by capturing the distributed state of the query plan being executed. 这里 state 我想类似于 PG plan state 那些状态,
So, the query processor has to incorporate its progress in the table’s key space in the restart token in order to be able to support the restart guarantees, even in presence of complex data transformations. 这里 ‘progress in the table key space’ 应该类似于 encoded primary key, and the snapshot timestamp.
我有个想法, 就是如果每个算子的输出都保证有序的话, 即每个算子的输入也都是有序的; 在 Spanner 中, 保证算子输出有序应该成本不是很高, 毕竟 Spanner 存储层是有序的. 这时我们需要在 DU 时, 在 union 时做一次归并排序, 类似于 Ordered Gather Motion, 就可以继续保证输出仍然有序. 而且我们之前测试过, 在 plan tree 不变的前提下, 有序的输入能极大地提升 Cache 命中率等局部性效果, 对查询也有加速作用. 这里我们需要排序算法本身是稳定的.
那么可以将算子的输入/输出想像成一个流, 可以通过 <排序列的值, encoded unique id> 来唯一地标识流中一个特定的位置, 这里流是按照 ‘排序列’ 来进行排序的. 这里 encoded unique id 取决于算子:
-
对于非 join, 非 group 算子来说; 输出流 ‘排序列’, encoded unique id 就等同于输入流 ‘排序列’, encoded unique id; Scan 算子的 encoded unique id = encoded primary key. Scan 算子的 ‘排序列’ 就等同于 primary key.
-
对于 group 算子, 输出流 ‘排序列’, encoded unique id = group by 的 columns .
-
对于 join 算子来说, 输出流 ‘排序列’ = ‘left.排序列’ + ‘right.排序列’; 输出流 ‘encoded unique id’ = ‘left.encoded unique id’ + ‘right.encoded unique id’.
这样每个算子只需要两个 restart token 即可实现 query restart, 此时 restart token 就是 <排序列的值, encoded unique id>:
-
restart token 1, 记录了当前算子输入流中的某个位置, 在这个位置之前的数据都已经被当前算子处理.
-
restart token 2, 记录了当前算子输出流中的某个位置, 在这个位置之前的数据都已经被当前算子吐出给下游算子.
类似于 Flink snapshot 的 barrier, 只不过这里每一行都可以作为 barrier. 大体思想如此, 但具体细节有待进一步斟酌.
7. BLOCKWISE-COLUMNAR STORAGE
这里提到的 Ressi data layout 非常类似于我之前的一个脑洞 为 rocksdb 引入 orc. 事实上, 我当时已经在 pebble codebase 上做了这个 prototype. 但由于并行扫描效果不理想, 在大数据量下扫描耗时挺长的. 并行扫描效果不理想的原因是因为对 N + 1 层 ORC 的扫描依赖于前 N 层, 毕竟这里 ORC 是按照 LSM tree 组织的. 当时就弃疗了, 但现在看来不是不可以救一下.
主要在于我们不再采用传统 hash 分布的方式来分割数据, 而是像 Spanner 一样采用 range 分布. 采用 range 分布的好处是我们可以更加激进地切分出更多的 shard, 使每一个 shard 的数据量尽可能地少, 那么单个 shard 内能不能并行 scan 无所谓.
Q: 为什么 hash 分布时我们不能激进地切分出更多的 shard?
A: 我理解是为了避免影响 TP 的性能. 以 Greenplum 为例, 设表 table1 primary key pk1, 用户日常 TP SQL 为 update/delete xxx where pk1 between yyyy and zzz, 由于 GP 中 table1 按照 pk1 hash 分布, 对于 pk1 between yyyy and zzz 这种条件, GP 不得不将 sql 下发到集群中所有 segment, 即集群中所有 segment 都参与了这一分布式事务. 而如果按照 pk1 range 分布, 那么将极大地降低参与分布式事务的 ‘参与者’ 数量, 从而提升 TP 效率.
另外 range 分布的话, 也更方便地做 split/merge, 根据需要动态切换出更多的 shard, 或者合并 shard.
这也是 KuiBaDB 下一步的方向.