最近在做的一些事对性能要求极其苛刻, 以至于最后不得不下潜到指令级找寻一些可能存在的优化点. 这里总结记录了在此过程中所得到的一些通用化优化规则. 在试图应用这些规则来优化自己的程序之前要首先铭记先贤们说过的: “过早优化是万恶之源”. 因此我们建议除非是使用了 perf 等工具找到了程序热点, 否则不应该首先应用这些规则来对程序进行优化. 我个人认为在写代码的过程中惦记着怎么把这段代码最优化这件事情只会徒增心智负担. (除非写出最优化的代码已经变成了一种肌肉记忆…
尽量避免有符号无符号整数的混用
根据 C/C++ 语言标准以及 GCC 实现姿势, 可以看到具有相同 size 的有符号无符号整数类型的互相转换并不会生成额外的指令.(完整的整数转换规则可以看 GCC 中的整数转换). 所以一般情况下, 混用具有相同 size 的有符号无符号整数类型并不会产生任何额外的代价. 但总是会有例外的时候, 尤其是在与 __builtin_mul_overflow()/__builtin_add_overflow() 等函数混用的时候. 如下代码片段:
constexpr uint64_t kM[] {
1,
};
int64_t X(int64_t l, int64_t r) {
int64_t ls = l & 0x3;
int64_t rs = r & 0x3;
int64_t dsts;
bool of;
if (ls > rs) {
dsts = ls;
of = __builtin_mul_overflow(r, kM[ls - rs], &r);
} else {
dsts = rs;
of = __builtin_mul_overflow(l, kM[ls - rs], &l);
}
l += r;
l |= (((int64_t)of) << 3);
return l;
}
在通过 GCC 编译生成汇编之后, 再使用我之前写的 as2cfg 工具将生成的汇编转换为控制流图, 可以看到此时控制流图中控制流的复杂远超过了预期:
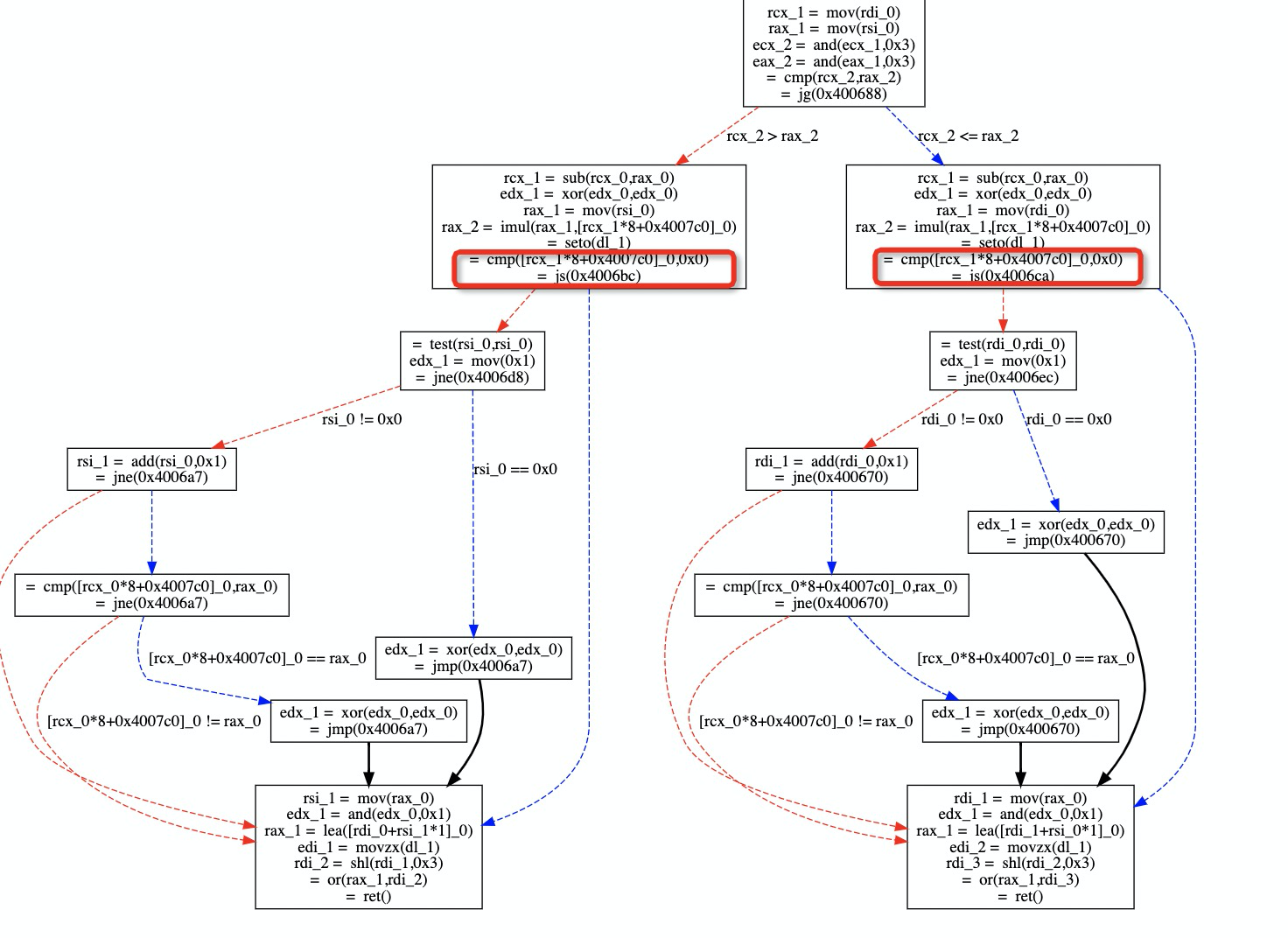
尤其是 cmp 之后紧跟着 js 的操作, 愣是让我在源码中找了半天没找到对应的位置. 考虑到 js 是判断 sign bit, 怀疑到可能是 __builtin_mul_overflow() 导致的, 进而意识到可能是 kM 类型导致的问题. 然后在把 kM 从 uint64_t 换为 int64_t 之后, 再次编译生成控制流图:
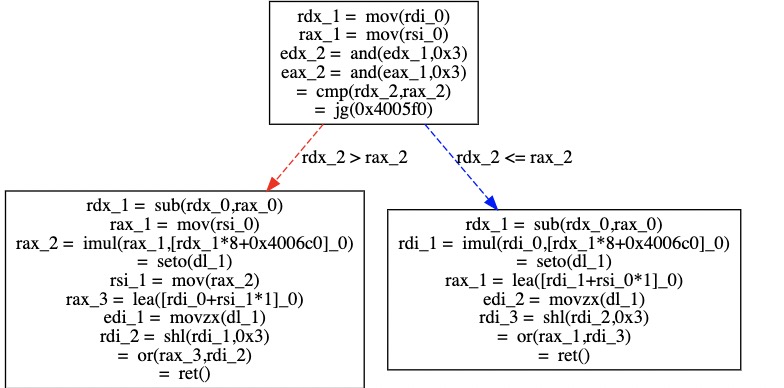
这次就非常清晰明了嘛!
之所以发现这个问题还是因为我从 perf report 的结果中看到一个莫名的 js 指令占用了 4% 左右的 cycles(说大倒也不大…):

实际上最开始我在写代码的时候 kM 的类型就想着是 int64 来着, 只不过最后不知道咋写成 uint64 了…
总是使用 int 及以上来作为整数类型
这里更准确的说法是: 对于一个可用 int/unsigned int 类型表示的整数类型变量, 若其只会参与与其他 int/unsigned int 类型变量的运算, 那么使用 int/unsigned 来保存该变量即可. 若该变量可能会与 long/unsigned long 或者更大的整数类型(如: __int128 等)变量放在一起运算, 那么就使用 long/unsigend long 来保存她. 换而言之, 不要去使用 short/int8_t 这种类型.
之所以如此主要是由于两方面原因, 一方面在 C/C++ 语言标准上指定了:
arithmetic operators do not accept types smaller than int as arguments, and integral promotions are automatically applied after lvalue-to-rvalue conversion, if applicable.
也就是两个 short 类型变量在相加时会被首先提升为 int 类型然后再做加法运算. 另外一方面根据 GCC 对整数类型的转换实现可知, 不同 Size 的整数在转换时可能是需要额外指令介入的, 比如 int32 到 int64 是需要一条 CDQE/movsx/movzx 指令的.
我个人在此之前都是能用小类型就不上大类型, 直到我看到 perf report 中各种 movzx/movsx/cdqe 等指令所占的 cycles 百分比…
返回多个值时返回 struct 可能会更高效
一般情况下针对需要返回多个值的情况, 我个人习惯通过返回值来返回主要的信息, 其他信息通过指针来传递, 就像 strtol() 所做的那样. 在这种做法下, 当编译跨越了多个编译单元或者库边界以至于编译器无法进行内联等优化措施之后, 每次这种函数的调用, 编译器都不得不在栈上为那些通过指针来传递的信息分配空间. 当然在大部分情况下, 这种并不会导致太大的性能问题.
但我们有机会做到更好, 通过调研文章函数调用的背后中提到的 ABI 标准, 我们可知对于类 struct {long a; long b} 这种结构体的参数, 将会依次尝试使用寄存器 rdi, rsi, rdx, rcx, r8, r9 来传递; 对于这种结构体对应的返回值, 也会借助于寄存器 rax, rdx 的使用来返回值. 即对于:
struct X {
long a;
long b;
};
X f(X a1, X a2);
GCC 将使用 rdi 来传递 a1.a, rsi 来传递 a1.b, 通过 rdx, rcx 来传递 a2.a, a2.b, 通过 rax, rdx 来返回返回值对应的 a, b 字段信息. 不会涉及到对栈的访问.
对于其他类型的参数与返回值是如何传递与返回的介绍可以参考上面提到的 ABI 标准文档.
还是那句话, 一定要在 perf 有明确证明之后再试图进行这些优化, 在我这个 case 中, 由于函数 Y 的声明是 uint64 Y(uint64 l, uint64 r, uint8 *flags), 因为另一个库中函数 X 在调用 Y 上不得不为 flags 在栈上分配个空间出来, 这导致了 perf report 的结果感觉不太好看:
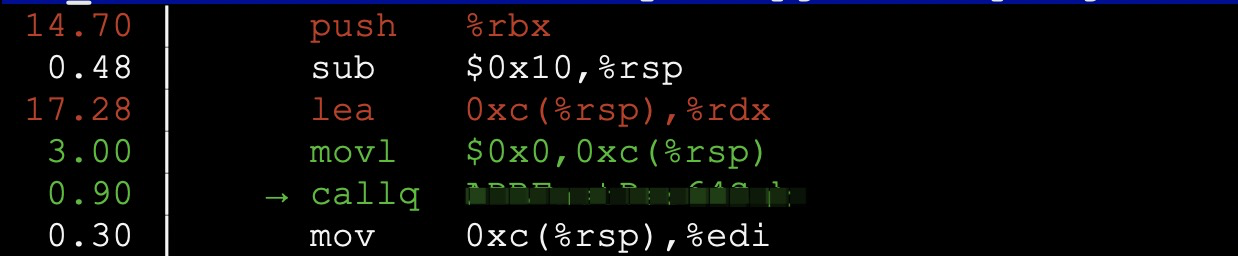
这里 0xc(%rsp) 存放着变量 flags, 在调用函数 Y 时, 寄存器 rdx 存放着 flags 的地址, 可以看到负责将 flags 地址更新到寄存器 rdx 的指令 lea 占了不少的 cycles. 当然也有可能只是个误报, 毕竟根据 perf 手册:
That means that the instruction pointer stored in each sample designates the place where the program was interrupted to process the PMU interrupt, not the place where the counter actually overflows. For this reason, care must be taken when interpreting profiles.
但是能优化一点是一点嘛..