如果需要在系统中实现一个支持用户自定义数据类型的功能, 你该怎么做? 如果是我的话, 我在系统中将只负责为这个数据类型提供一个定长/变长的存储空间, 之后关于对这个存储空间的使用与解析全部交于用户去做. 在 PG 中, 也是类似做法. PG 中使用长度固定为 8 字节(起码在 64 位机器上)的 Datum 来表示所有的用户数据类型. 即 Datum 肩负着在 PG 内核与用户代码之间传递数据的责任, PG 内核与用户代码都将遵循一系列约定来构造与理解一个 Datum 对象.
若用户类型指定为变长么, 那很显然 Datum 自身是不足以用来存储数据的. 此时 Datum 类型中存放的值认定为是一个地址, 该地址指向着存放着用户数据的空间, 该空间前 4 bytes 总是存放着该空间总长度, 以及一些元信息; 该空间后面区域完全由用户自己使用. 对于变长类型, 根据类型 typstorage 属性取值, PG 在将该类型数据存放在 heap file 中时, 可能会对数据进行压缩或者 toast 化等处理. 我本来这种处理只会发生在存储层, 即在数据存入时, 根据需要进行 toast 化, 压缩等处理. 在数据取出时, 进行 decompress, detoast 等逆化处理. 使得对于上层来说, 对于变长类型的 Datum, 其前 4 byte 总是单纯地存放着地址, 后面存放着原生用户数据, 看不到任何 toast, compress 等事实.
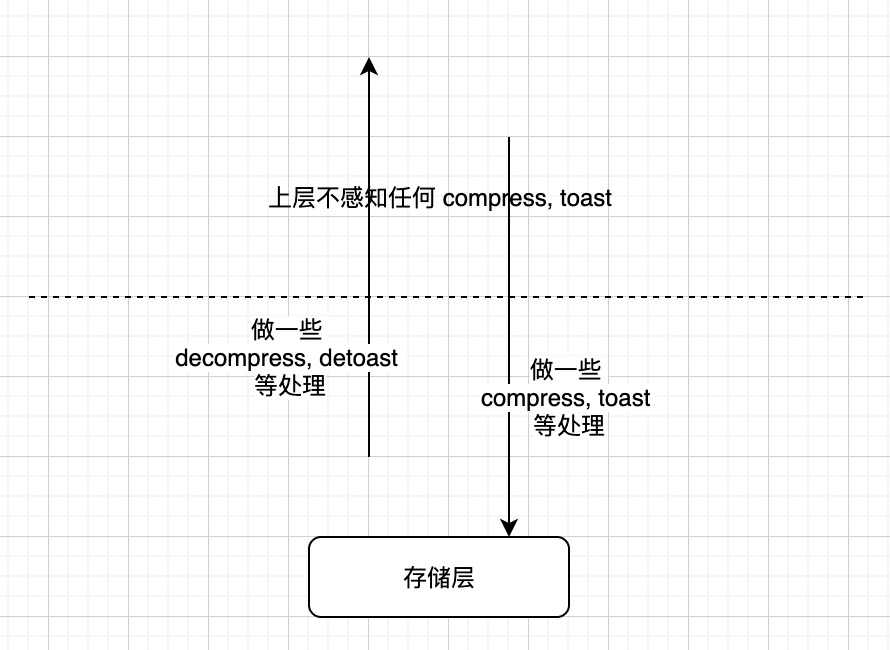
但可能是出于性能与效率等因素考虑, 在 PG 从存储层取出数据之后, PG 并不会立刻进行 detoast, decompress 等处理, 而是直接交于上层, 上层在需要时手动调用相关函数进行 detoast, decompress 等处理. 这意味着当我们在运行时遇到一个变长类型对应的 Datum 对象时, 它可能已经被 compress 或者 toast 了. 另外除了 compress, toast 之外, PG 可能也会对 Datum 对象进行 1-byte length 化处理, 当 PG 发现仅使用 1-byte 便能够保存长度信息时, 便会这么做, 此时用户数据不会有任何处理. 因此这里我们总结一下:
-
对于接受变长类型作为函数参数的用户代码来说, 表示其参数的 Datum 对象可能被 toast 或者 compress 或者 1-byte length 等处理. 若用户代码需要访问 Datum 对象中存放着的用户数据, 其总应该像 byteaout 那样:
Datum byteaout(PG_FUNCTION_ARGS) { // PG_GETARG_BYTEA_PP() 会进行必需的 detoast, decompress 处理. bytea *vlena = PG_GETARG_BYTEA_PP(0); // 此时 vlena 可能是 1-byte length, 或者是 4-byte length. // 如下 VARSIZE_ANY_EXHDR(), VARDATA_ANY() 宏会判断实际情况并相应处理. char *result; char *rp; if (bytea_output == BYTEA_OUTPUT_HEX) { /* Print hex format */ rp = result = palloc(VARSIZE_ANY_EXHDR(vlena) * 2 + 2 + 1); *rp++ = '\\'; *rp++ = 'x'; rp += hex_encode(VARDATA_ANY(vlena), VARSIZE_ANY_EXHDR(vlena), rp); } *rp = '\0'; PG_RETURN_CSTRING(result); } -
对于返回变长类型对象的用户代码来说, 可以像 byteain 那样总是返回未进行任何 toast, compress, 1-byte length 处理的 Datum 对象. 记得这样的 Datum 对象用户数据长度最大为
2 ** 30! byteain() 这里未进行任何溢出判断处理, 应该是 PG 从协议层限制了 inputText 长度不会超过2 ** 31, 因为在 libpq 代码中,pg_conn::outBufSize的类型是 int, 也即 libpq 发送的包的最大长度就是2 ** 31 - 1!Datum byteain(PG_FUNCTION_ARGS) { char *inputText = PG_GETARG_CSTRING(0); char *tp; char *rp; int bc; bytea *result; /* Recognize hex input */ if (inputText[0] == '\\' && inputText[1] == 'x') { size_t len = strlen(inputText); bc = (len - 2) / 2 + VARHDRSZ /* sizeof(uint32) */; /* maximum possible length */ result = palloc(bc); bc = hex_decode(inputText + 2, len - 2, VARDATA(result)); SET_VARSIZE(result, bc + VARHDRSZ); /* actual length */ // 这里返回的 result 并未进行任何 toast, compress, 1-byte length 处理. PG_RETURN_BYTEA_P(result); } /* ... 省略 ... */ }
对于定长的用户类型来说, 我们还需要结合类型的 typbyval 属性来理解与构造 Datum. 若 typbyval 为 false, 则 Datum 值被认定为是一个地址, 其指向着长度固定为 typlen 的空间, 该空间全部用于用户数据的存放. 若 typbyval 为 true, 这表明 typlen <= sizeof(Datum), 准确来说 typlen 只能为 1, 2, 4, 8. 此时用户数据就存放在 Datum 对象自身中, 根据 typlen 不同依次占据着 Datum 对象低 1 字节, 2 字节, 4 字节, 或全部 8 字节.
typinput 的作用. 简单来说 PG 内核会将 INSERT SQL 中的字符串字面值作为参数交给 typinput 函数, 该函数对字符串字面值进行解析并生成返回 Datum 对象. 之后 PG 内核存储层按照上面所说的约定将 Datum 存入 heap file 中, 这部分逻辑可参考 heap_form_tuple().
typmodin, typmodout; 参考 CREATE TYPE 中对 type_modifier_input_function, type_modifier_output_function.
internal 类型参数, 若函数参数是 internal 类型, 则表明该函数不能通过 SQL 来调用, 只能被该函数所在模块来内部调用, 对 internal 类型参数的解释取决于模块自身约定.