记录着一些有趣的事儿. 可能是亲身经历的, 也可能是八卦听说来的. 我平日最喜欢八卦围观各种 bug. 对于其中一些令人拍案惊奇的 bug 会脱敏之后放在这里.
困在 facebook/wangle 的凌晨三点
这是在百度参与开发百度分布式消息队列 Bigpipe 时遇到的. 在某次大版本开发中, 我们非常激进地引入 facebook/wangle 来作为我们的异步编程框架, 希望能为我们的服务带来更好的并发能力. 关于我们是如何进行异步编程的, 可以参考 异步编程模式. 没想到这恰恰是噩梦的开始.
在灰度时, 服务出现了 core 的情况, 虽然频率不是很频繁. 但总是让人如鲠在喉啊! 而且崩溃发生时堆栈也不尽相同. 根据经验猜测是发生了 use-after-free 类似现象. 但问题是, 在大版本开发中, 引入了 C++11 以及 facebook/folly 提供的各种智能指针, 代码本身从未显式调用过 new/delete, 不应该存在这类内存相关问题啊.
直到那天到来, 2018-08-22 晚上 9 点左右, 机缘巧合之下从日志中发现一丝怪异之处. 一个特定的物理连接两次进入最终状态! 如 异步编程模式 中所述, 我们采用了状态机来管理物理连接的生命周期. 预期情况下, 任一一个物理连接进入最终状态之后, 就会被进行资源释放操作, 绝不该有再次进入最终状态的情况发生. 而这点是根据 ‘folly::AsyncSocket 在 close() 返回之后, 其上不会再有任何事件发生’ 来保证的. 所以当时就觉得 folly::AsyncSocket 存在语义不一致情况, 其在 close() 之后仍会有读写事件发生, 仍会调用应用的事件处理回调. 但是在仔细琢磨了 folly::AsyncSocket 源码之后, 发现并不会存在这种情况, folly::AsyncSocket 是没啥毛病的. 整件事情好像又一次陷入泥潭中, 我也准备去赶百度最后一班末班车了.
在地铁上发呆的时候, 忽然意识到, 其实我们并未直接使用 folly::AsyncSocket, 而是通过 wangle::Pipeline 来进行读写, 会不会是 wangle::Pipeline 存在着语义不一致情况, 在套接字被关闭之后, 仍会调用我们的事件回调函数?!
最终发现了事实确实如此, 锅出现在 wangle::ByteToMessageDecoder 身上, 如下是其部分源码:
void read(Context* ctx, folly::IOBufQueue& q) override {
bool success = true;
do {
M result;
size_t needed = 0;
success = decode(ctx, q, result, needed);
if (success) {
ctx->fireRead(std::move(result));
}
} while (success);
}
ctx->fireRead(std::move(result)); 这里会调用到我们的事件处理函数. 而且还可以看到如果我们在事件处理里面关闭了当前 socket, ByteToMessageDecoder::read() 仍可能会再次调用 fireRead, 从而再次进入我们的事件处理函数中. 在对 ByteToMessageDecoder 做了修改之后, 上述的 core 现象终于也不会出现了.
到了今天大半年已经过去了, 这个问题很多细节应该不太记得了, 唯一还留有深刻印象的就是当时发的一条朋友圈, 以及一个已经合入 facebook/wangle master 分支的 PR.
神秘的 100 continue
还是在百度 Bigpipe 项目组时发生的事儿, Bigpipe 除了常规的与 kafka 类似的订阅方式之外. 还支持主动将新发布的信息推送给用户配置的 http 服务上. 具体就是在新消息到来时, 往指定的地址发送一条 POST 请求, 带上新发布的消息内容以及相关元信息. 然后就有一个业务方反馈.
消息投递延迟超过了 1 秒, 由于情况并不是很常见, 而且对业务也没什么太大影响, 所以我们也一直没有放在心上, 以为是 bigpipe 系统压力大, 或者业务方 http 服务压力大导致的抖动情况. 直到有一天, 我在配合我们的测试妹子搭建消息推送这一场景的测试环境时, 复现了这一情况, 消息投递延迟在 1 秒多点, 而且当时无论是 bigpipe, 还是 http 服务, 压力都不怎么大. 于是在 Bigpipe 消息推送服务所在节点起了个 tcpdump, 再次尝试复现投递延迟大于 1 秒这一场景. 根据抓来包内容分析, 最终发现罪魁祸首元凶:

整件事情, 当我们消息推送服务发送的 POST 请求所携带的数据超过 libcurl 配置阈值时, libcurl 会首先发送个 Expects: 100-continue 首部, 期望对方 http server 返回个 100 continue, 然后再接着发送 POST 请求数据体. 但上面业务方所使用的 http 服务未进行正确配置, 其并不理解 http client 发来的 Expects: 100-continue 首部. 所以 libcurl 在等待 1 秒发现并没有 100 continue 之后, 就继续发送了 POST 请求数据体. 这就导致了在业务方看来, 消息投递延迟在 1 秒以上了! 而且由于业务方发布的消息体积很少有超过 libcurl TINY_INITIAL_POST_SIZE(1024 字节)配置值的, 所以投递延迟超过 1 秒情况出现频次也很低.
未能修复了的 core 遗憾
还是在百度 Bigpipe 项目组时发生的事儿, 在解决掉上面那个由于 facebook/wangle 自身 bug 而导致的 Bigpipe 服务 core 之后. 服务还是会有 core 的情况, 只不过频次更低了, 1 个月都可能赶不上 1 次. 老样子虽然一直再查, 但实在不怎么有头绪. 直到我都已经离职了, 在百度 icafe 上这个 issue 对应的卡片仍然没啥进展…
在离职之后, 待入职阿里期间. 除了日常陪怀孕的老婆遛弯之外, 就在研读 facebook/folly async 包内容. 在看 AsyncSocket 处理 write error 这段代码时震惊地发现代码中的逻辑与我预想的 write 错误处理逻辑很是不同. 就如同我在 异步编程模式 中所述, 每批 write 操作都会在最后一个 write 操作返回的 future 上注册 onError 事件, 期望能及时处理写错误发生. 在服务实际运行中, 一个 AsyncSocket 可能会多批 write 操作, 也就是有多个 on write error 事件被注册. 本来以为的是由于我在 onError 回调函数中, close 了当前套接字, 那么其他 on write error 回调要么不被调用, 要么在当前 onError 回调函数内调用. 如果在当前 onError 函数内被调用, 那么就会被 StartRst(), IsInRst(), EndRst() 这套机制保护着, 使得这些 onError 回调函数等同于 noop 操作. 也即无论哪种情况, 这些 on write error 回调只有一个是真正干活的. 但没想到 AsyncSocket write error 处理逻辑却是:
void AsyncSocket::closeNow() {
// ...
switch (state_) {
case StateEnum::ERROR:
// Do nothing. The error handling code has performed (or is performing)
// cleanup.
return;
// ...
}
// ...
}
void AsyncSocket::failWrite(const char* fn, const AsyncSocketException& ex) {
startFail();
// startFail() 会 state_ = StateEnum::ERROR;
// Only invoke the first write callback, since the error occurred while
// writing this request. Let any other pending write callbacks be invoked in
// finishFail().
// 调用当前注册了的 write callback!
if (writeReqHead_ != nullptr) {
WriteRequest* req = writeReqHead_;
writeReqHead_ = req->getNext();
WriteCallback* callback = req->getCallback();
uint32_t bytesWritten = req->getTotalBytesWritten();
req->destroy();
if (callback) {
callback->writeErr(bytesWritten, ex);
}
}
finishFail();
}
在 callback->writeErr(bytesWritten, ex) 时, 会调用应用层注册的 onError(), onError() 会调用 closeNow() 来关闭当前套接字. 由于之前的 startFail() 会 state_ 置为 StateEnum::ERROR. 导致了 onError 回调内的 closeNow() 变为了 noop. 就导致了 onError() 会被连续调用多次, 不再符合预期, 自然就会出现预期之外的坑了~!
遗憾地是由于已经离了职, 所以事情究竟是不是这样也不晓得了. 不过八九不离谱了. 当然这些也是热心地给老同事们反馈了一下, 不知道他们有没有给修了.
Hadoop ChecksumFileSystem 天秀的 setPermission 姿势
Hadoop ChecksumFileSystem::setPermission, 经过一堆调用链之后最终会通过启动个 chmod 进程来为新建文件设置权限. 这直接导致我们线上 CPU 利用率飙满. 具体来说, 就是我们的分布式 OLAP 产品 ADB采用了存储计算分离架构, 其数据是放在阿里自研的分布式文件系统盘古上. ADB 中通过 org.apache.hadoop.fs SDK 来访问存储于盘古上的数据. 具体来说, ADB 将会通过 org.apache.hadoop.fs.FileSystem#copyToLocalFile() 来下载文件到本地, 然后 hadoop fs 将使用 org.apache.hadoop.fs.LocalFileSystem 来访问位于本地磁盘上的文件数据. 然后 LocalFileSystem::create() 实现如下:
@Override
public FSDataOutputStream create(Path f, FsPermission permission,
boolean overwrite, int bufferSize, short replication, long blockSize,
Progressable progress) throws IOException {
Path parent = f.getParent();
if (parent != null && !mkdirs(parent)) {
throw new IOException("Mkdirs failed to create " + parent);
}
final FSDataOutputStream out = new FSDataOutputStream(
new ChecksumFSOutputSummer(this, f, overwrite, bufferSize, replication,
blockSize, progress), null);
if (permission != null) {
setPermission(f, permission);
}
return out;
}
而上面 setPermission() 函数经过一堆调用链之后会调用到 org.apache.hadoop.fs.RawLocalFileSystem::setPermission(), 该函数实现如下:
@Override
public void setPermission(Path p, FsPermission permission
) throws IOException {
execCommand(pathToFile(p), Shell.SET_PERMISSION_COMMAND,
String.format("%04o", permission.toShort()));
}
也就是每次 LocalFileSystem::create 都可能会启动一个 chmod 进程.
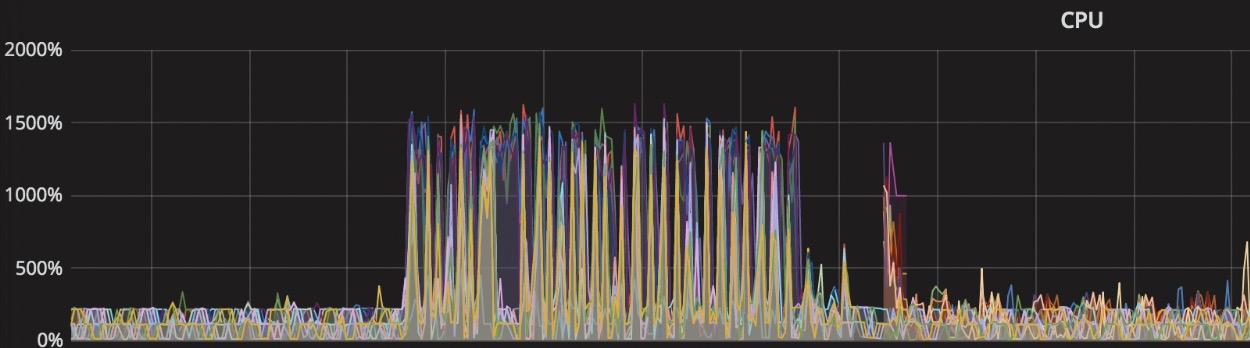
在 ADB 中, 当用户数据库的规模非常大时, 在某一时刻可能会并行地从盘古上下载很多文件到本地, 由于之前的 LocalFileSystem::create 都会启动一个 chmod 进程. 这直接导致了我们 CPU 开始飙满. 如下图:
jstack 可以看到线程堆栈为:

在修复之后, 在同样的场景下, cpu 利用率如下图:
千万不要相信从网页上复制来的内容
最近在主持一场对我们的分布式 OLAP 产品 ADB压测行动. 主要是验证某次 fix 对性能地提升. 在第一天对老版本的压测之后, 为了后续压测方便, 我将压测命令保存在阿里内部的工单系统 aone 上. 在第二天应用了 fix patch 之后, 直接复制了网页上保存着的压测命令开始了压测. 这次压测效果异常地好, 粗略计算来看性能提升了至少 50 倍. 大家都是非常的开心. 但是,
我日常打开了 grafana 查看在压测过程中各种指标信息, 震惊地发现数据库连接数在压测期间只有 1 个! 一种不祥地预感涌上心头, 按理来说数据库连接数至少要不小于在压测时指定的并发数才对! 再给压测程序加了一些 log, 经历了无数次尝试之后震惊地发现了如下事实:

看起来完全相同的命令行却导致了完全相反的输出. 加上 od 之后, 才发现一些幺蛾子:
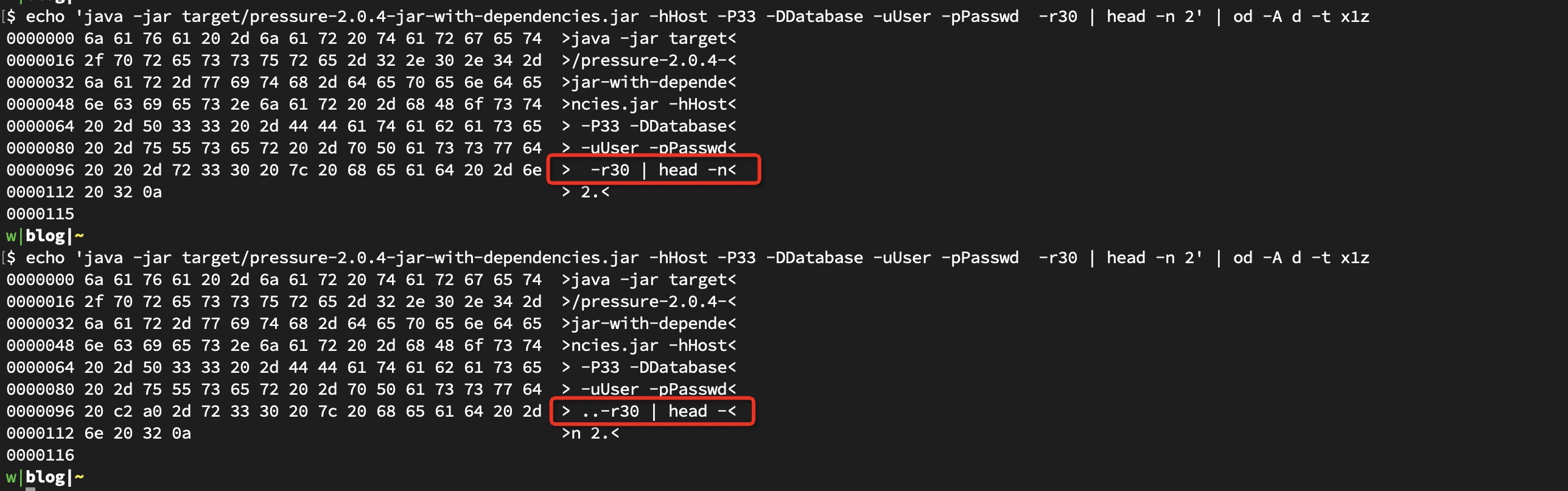
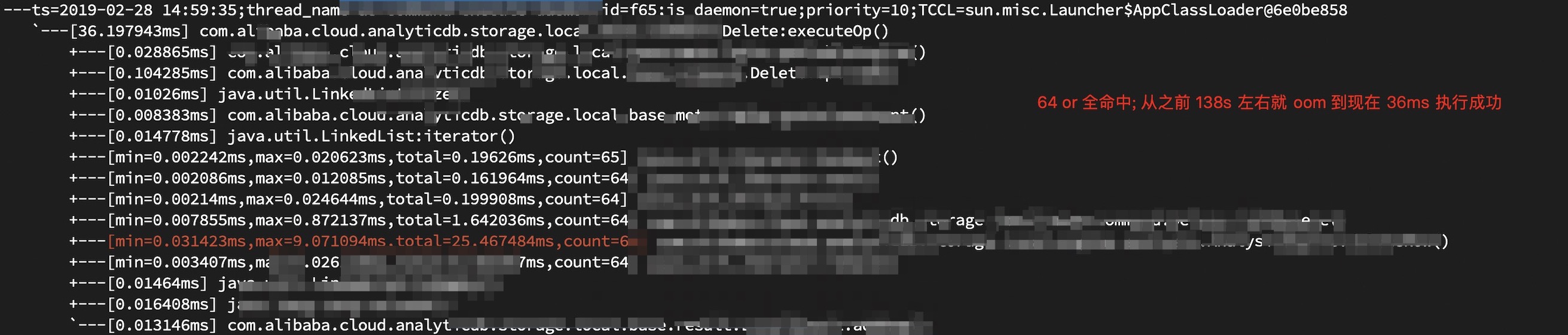
由于多余的两个字符导致 -r 选项被认定是不存在的, 所以走了默认值 1 了.
我曾经将程序性能优化了至少 3000 倍
还是在我们的分布式 OLAP 产品 ADB中, 较为常见的用户案例是与 阿里云 RDS, 阿里云 DTS 搭配在一起使用, 具体就是 rds 用作 oltp 库, adb 用作 olap 库, dts 负责将 rds 的 dml 操作同步到 adb 中. 为了提升同步效率, dts 引入了启发式 dml 聚合算法. 就是将多条基于主键删除的 DELETE 语句通过 OR 运算符聚合形成一条 DELETE 语句. 如将 DELETE FROM table WHERE primarykey = val1, DELETE FROM table WHERE primarykey = val2 聚合成 DELETE FROM table WHERE primarykey = val1 OR primarykey = val2. 极端情况下 OR 运算符数量会在 100 个左右. 然后 ADB 的 DELETE 链路用了非常朴素的操作, 就是中规中矩地查找, 然后再一一删除. 在此场景大量 OR 运算符下, 查询堆栈会非常地深, 直接导致查询执行很久甚至无法正常完成.
我当时所做对此的优化就是将 DELETE WHERE 条件按照 OR 进行拆分, 将 OR 运算数存放在 orOps. 如下:
// 按照深度优先遍历 cond. 生成结果与 cond 具有相同的结合性以及优先级.
private static LinkedList<Expr> splitOR(Expr root) {
LinkedList<Expr> ret = new LinkedList<>();
// 之所以不用 ArrayDeque, 是因为不能塞 null 值.
ArrayList<Expr> stack = new ArrayList<>(16);
push(stack, root);
while (!stack.isEmpty()) {
Expr exp = pop(stack);
if (!(exp instanceof ExprAndOr)) {
ret.add(exp);
continue;
}
ExprAndOr expOr = (ExprAndOr)exp;
if (expOr.getAndOrType() != ExprAndOr.OR) {
ret.add(exp);
continue;
}
push(stack, expOr.getRight());
push(stack, expOr.getLeft());
}
return ret;
}
然后遍历 orOps, 对于每一个 OR 操作数, 如果其是一个基于主键的删除, 则直接删除该行. 最后对于 orOps 中剩下的, 无法基于主键的删除, 再使用 OR join 生成一个表达式, 走普通的查询引擎进行普通的删除.
此番操作直接将 DTS 发来的 DELETE 语句执行时间从 138s 提升到 40ms 左右.