在一次对 分析型数据库PostgreSQL版(下称 ADB PG版) 的日常测试中, 发现了日志中报 deadlock detector 错误. 一开始并未当回事, 毕竟能被 PostgreSQL 的 deadlock detector 检测到的死锁应该不是啥大问题. 所以写了个小脚本, 周期性抓取 pg_locks 并输出到文件, 这一看不得了了.
触发 deadlock detector 的 SQL pattern 如下所示, 该 SQL 会被多并发地周期性运行. 其中 i, j 是表 table 的主键, table 本身也是一个一级分区表.
BEGIN
DELETE FROM table WHERE i = $1 AND j = $2
INSERT INTO table VALUES(...)
COMMIT
在 ADB PG版中为了避免分布式执行 delete/update 导致的死锁, 默认配置下会在 delete/update 时对待删除的表加上 Exclusive 锁. 所以理论上如上 SQL 在 DELETE 执行成功之后, 表明已经拿到了 table 上的表锁, 那么后面 INSERT 执行在拿行锁的时候理论上会是顺风顺水的, 不会有丝毫阻塞的. 但是如下实际运行日志却是报错, 事务 6263056 在执行 INSERT 获取行锁时被 PG 检测到死锁了. 这意味着 LockAcquire 函数在等待 deadlock_timeout(默认 1 秒)时间内仍未获取到锁, 之后触发了 CheckDeadLock(), 并被检测到死锁存在. 但理论上在同一事务内先执行的 DELETE 执行结束后, 事务就会已经持有了 table 身上的表锁, 所以 LockAcquire() 在进入 ProcSleep() 时就能检测到这一事实从而立刻获取锁并返回.
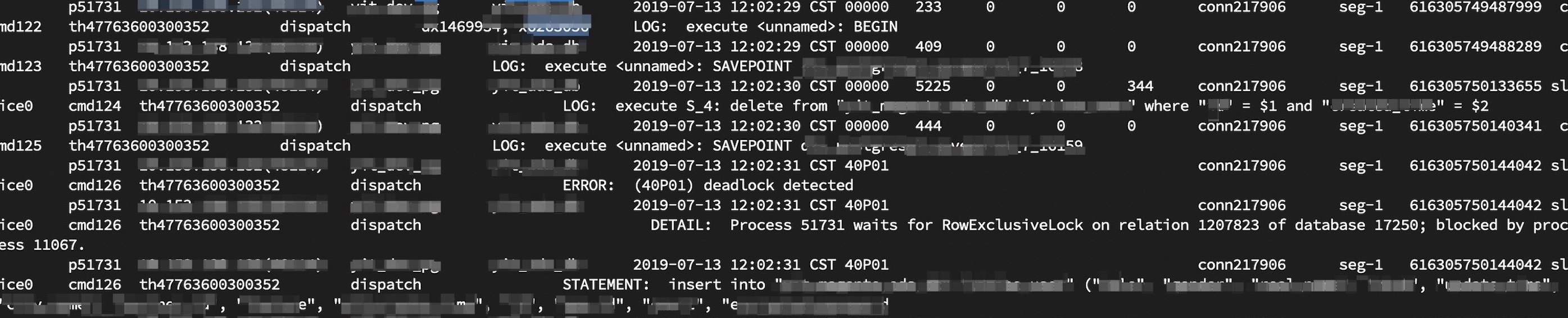
而且从抓到的 pg_locks 中看到的情况更为诡异, pg_locks 显示当前事务 6263056 并未持有任何与表 table(oid=1207823) 相关的锁, 仅仅能看到执行 INSERT 时尚未获取到的行锁. 另外一方面也显示进程 11067 当前正在持有着 table(oid=1207823) 身上的表锁. 而且从日志上看, 进程 11067 也确实导致了事务 6263056 被 deadlock detector.
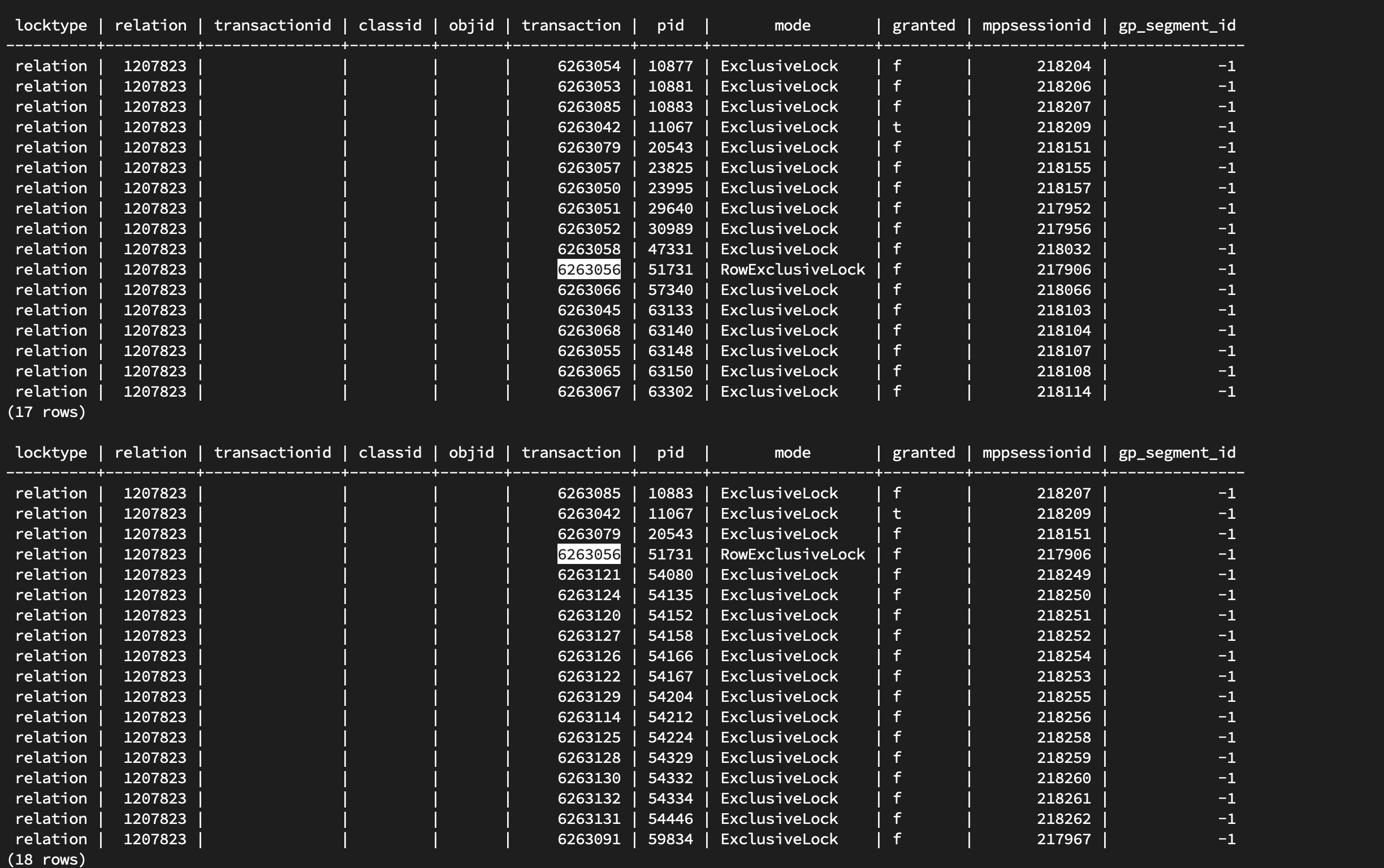
考虑到 deadlock_timeout 仅有 1 秒, 所以如上 pg_locks 显示的信息至多存在 1 秒, 所以能抓到真是
至此第一反应是头大了: DELETE 拿到的表锁在事务执行期间被提前释放了! 于是召唤 GDB, 试图打印出每一个 backend process 获取锁/释放锁的记录, 来尝试发现 DELETE 加的表锁被何时释放掉了. (PG 中每一个事务开始时都会对事务 id 加个 exclusive lock, 所以可以通过这条加锁记录来确定事务边界.
# deadlock.gdb
set target-async on
set non-stop on
set pagination off
set logging file deadlockaaa.log
set logging redirect on
set logging on
handle all nostop noprint pass
# locallock->nLocks > 0 时, LockAcquire 完全操作当前 backend 进程中存放着的 LOCALLOCK 信息.
# 并不会访问 shared memory 中的 LOCK, PROCLOCK 等信息, 完全本地化操作. 不应该会诱导出本次死锁, 所以不 care, 跳过.
#
# locktag_type = 0 && locktag_field2 < 16384, 意味着加锁操作发生在 oid < 16384 的那些 relation 上, 都是一些 system catalog,
# 也不应该导致本次死锁, 所以也跳过.
b GrantLockLocal if locallock->nLocks <= 0 && (locallock->tag.lock.locktag_type != 0 || locallock->tag.lock.locktag_field2 >= 16384)
commands
silent
printf "GrantLock;pid:%d;field1:%u;field2:%u;field3:%u;field4:%u;type:%u;methodid:%u;mode:%d\n",MyProcPid, locallock->tag.lock.locktag_field1, locallock->tag.lock.locktag_field2, locallock->tag.lock.locktag_field3, locallock->tag.lock.locktag_field4, locallock->tag.lock.locktag_type, locallock->tag.lock.locktag_lockmethodid, locallock->tag.mode
bt
cont &
end
b UnGrantLock if lock->tag.locktag_type != 0 || lock->tag.locktag_field2 >= 16384
commands
silent
printf "UnGrantLock;pid:%d;field1:%u;field2:%u;field3:%u;field4:%u;type:%u;methodid:%u;mode:%d\n",MyProcPid, lock->tag.locktag_field1, lock->tag.locktag_field2, lock->tag.locktag_field3, lock->tag.locktag_field4, lock->tag.locktag_type, lock->tag.locktag_lockmethodid, lockmode
bt
cont &
end
cont -a &
之后再召唤 screen 神器来使能 gdb 后台长期运行:
for pid in $(ps -o pid `grep -F 'DETAIL: ' PGLogFile.log | grep -oE 'blocked by process [[:digit:]]+' | awk '{print $4}' | sort -n | uniq` | grep -vF 'PID')
do
screen -U -d -m -S "deadlock-gdb-$pid" gdb --data-directory=xx -x deadlock.gdb -p $pid
done
完事后还整了个脚本来解析 gdb 采集到的加锁/释放锁记录, 试图发现一些不合理的加锁/释放锁行为:
# -*- coding: UTF-8 -*-
import sys
import logging
import re
logging.basicConfig(level=logging.INFO, format='%(asctime)s|%(process)d|%(thread)d|%(name)s|%(levelname)s|%(message)s')
locktagpattern = re.compile('pid:(\d+);field1:(\d+);field2:(\d+);field3:(\d+);field4:(\d+);type:(\d+);methodid:(\d+);mode:(\d+)')
def tolocktag(lineno, line):
res = locktagpattern.search(line)
return (lineno, (int(res.group(1)), int(res.group(2)), int(res.group(3)), int(res.group(4)), int(res.group(5)), int(res.group(6)), int(res.group(7)), int(res.group(8))))
def main():
instream = sys.stdin if len(sys.argv) <= 1 else open(sys.argv[1])
lineno = 0
lockstack = {}
for line in instream:
lineno += 1
if line.find('UnGrantLock;pid') != -1:
locktag = tolocktag(lineno, line)
if locktag[1] not in lockstack:
logging.warning('UnmatchedRelease;lineno: %s', lineno)
continue
lockstack[locktag[1]] -= 1
if lockstack[locktag[1]] <= 0:
lockstack.pop(locktag[1])
continue
if line.find('GrantLock;pid') != -1:
locktag = tolocktag(lineno, line)
lockstack.setdefault(locktag[1], 0)
lockstack[locktag[1]] += 1
continue
for locktag in lockstack:
logging.warning('NotRelease; locktag: %s; times: %s', locktag, lockstack[locktag])
return
if __name__ == '__main__':
main()
但实际上并没有任何用==.
最后还是在人肉看 gdb 采集到的加锁/释放锁日志时, 发现了一些端倪. 如下在一个事务开始之后紧跟着的居然是一条 bind message. 而 ADB PG版里面表锁是在 parse message 阶段加的. 并且根据 PG extended query protocol spec 来看, extended query protocol 交互中第一条消息总应该是 parse. 另一方面 extended query protocol spec 也指出 If successfully created, a named prepared-statement object lasts till the end of the current session, unless explicitly destroyed. An unnamed prepared statement lasts only until the next Parse statement specifying the unnamed statement as destination is issued. 所以若在一次 query 交互中省略掉 parse message, 直接发送 bind message, 那么 bind message 可以使用上次 parse message 的结果.
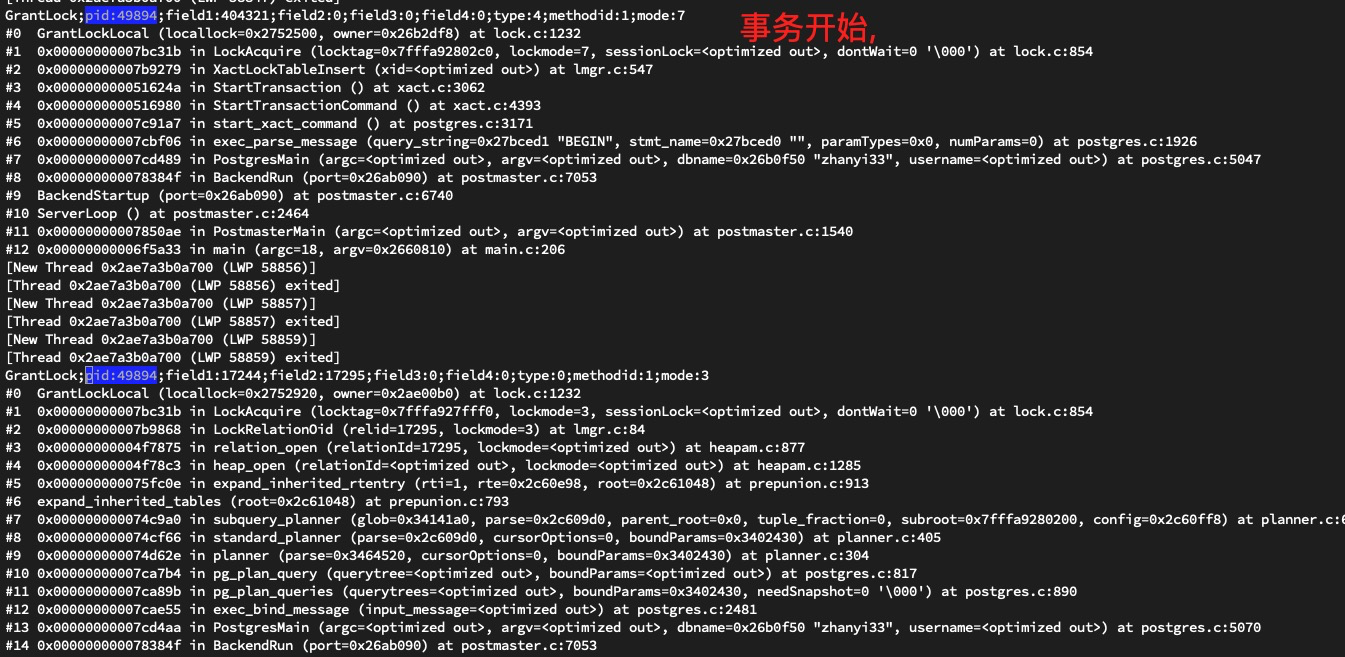
至此, 死锁原因也就清晰名了了. 客户端的某次事务在一次 query 交互中省略掉了 parse message, 导致本次事务未加表锁执行, 同时在相关配置未开启情况下导致了死锁.