时光荏苒,蓦然回首,自写下 从数据库到 AI 一文正式踏入 AI 领域,至今恰好一年。最近在整理述职 ppt 时,系统梳理了这段时间的学习与实践,索性也在这里做个简要总结,权当记录这段与 AI 共舞的成长旅程。
PD 分离: 为什么 HybridConnector
我刚来到 AI 时, 分布式推理正成为业界主流趋势, 大家都在探索如何通过PD分离以提升吞吐与降低成本; 而且非常幸运, 老板给了机会让我负责 vLLM PD 分离这块的设计与开发工作. 在探索 PD 分离的实现路径时,我调研了社区主流方案,发现它们普遍存在一些根本性问题。首先,很多方案让 Scheduler 主动感知 KV Cache 的 loading/saving 状态,通过下发 “空” 的 dummy step 来轮询更新状态。这种方式不仅混淆了 KV Cache 的 I/O 操作与计算任务,还在 Step 执行链路中引入了大量逻辑处理,带来了额外的复杂度和性能开销。
面对这些问题,我的个人观点也非常明确:LLM 引擎与 PD 分离就类似 linux 内核与驱动; 前者提供稳定、通用的核心能力,后者则根据具体硬件或生态灵活适配。PD 分离的具体实现高度依赖公司内部的技术栈,因此不应将任何 PD 相关逻辑硬编码进 LLM 引擎。LLM 引擎只需提供有限且克制的接口,遵循“如无必要,勿增接口” 的原则.
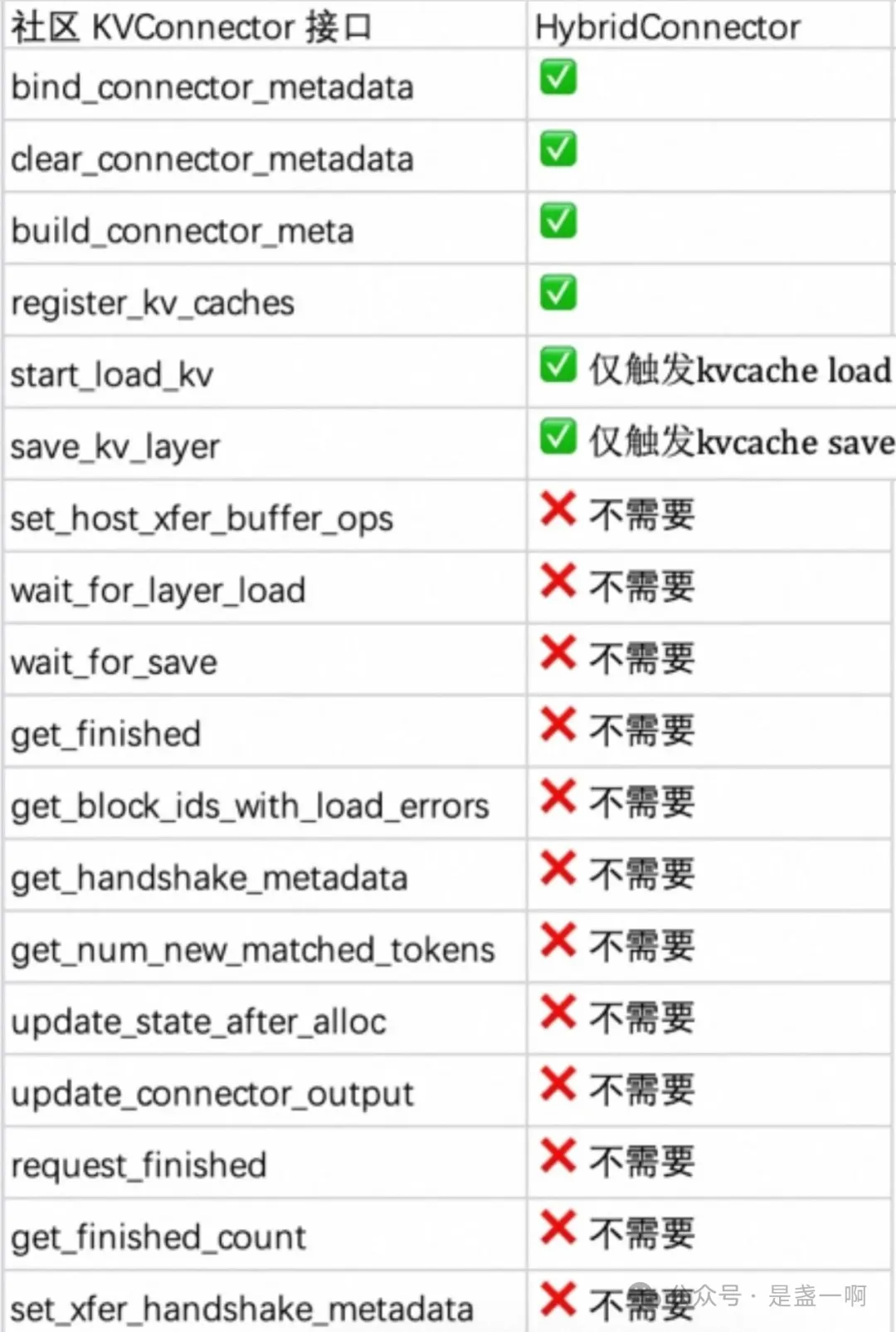
基于这一理念,我们设计了 HybridConnector:它不侵入引擎主链路,仅通过极简接口触发 KV Cache 的 load 和 save,其余所有逻辑均由 Connector 异步完成. 正如下面对比表所示,HybridConnector 只保留了必要的两个动作:start_load_kv 和 save_kv_layer,其他如 wait_for_save、get_finished 等冗余接口全部移除。这不仅大幅简化了引擎代码,也实现了真正的零侵入、全异步。
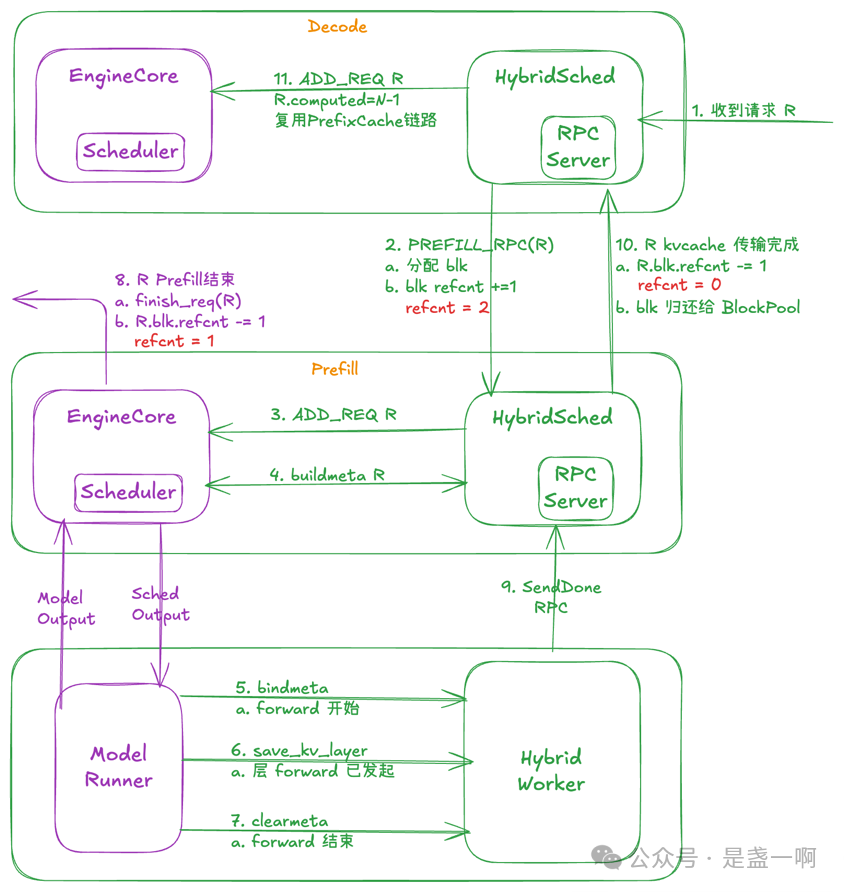
我个人最喜欢 HybridConnector 的一项创新在于:通过复用 vLLM 的 Block 引用计数(refcnt)机制,实现了 KV Cache 传输过程与请求生命周期的解耦。 具体而言,对于需要传输 KV Cache 的请求 R,HybridConnector 会在传输开始前,主动增加其对应 KV Cache Block 的引用计数。待异步传输完成后,再调用 KV Cache Manager 的 free_block 接口,将该 Block 的引用计数递减;当引用计数归零时,Block 会被自动回收至空闲列表(free list)。 这一机制确保了即使在请求已结束、但 KV Cache 仍在传输中的场景下,相关内存块也不会被提前释放.
PD 分离: kvtransfer
kvtransfer 是贴近 HybridConnector 要求设计的 kvcache transfer 模块, 其设计理念与细节已经在 这篇文章 详细介绍了.
HybridConnector: 不止PD分离
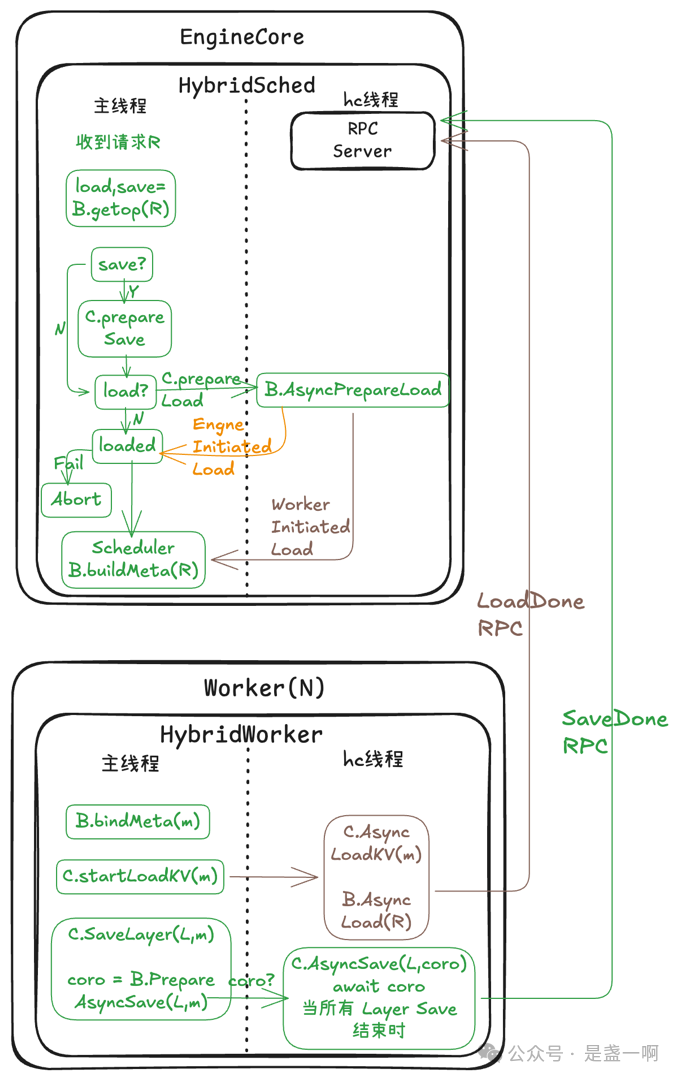
在完成 PD 分离之后,我意识到:我们构建的 HybridConnector, 它所解决的核心问题,其实是 KV Cache 的 “搬迁”。而这种搬迁需求,并不仅限于 Prefill 和 Decode 之间。比如:KVStore 持久化:需要在显存与共享存储之间搬迁 kvcache;请求迁移:需要将 KV Cache 在原节点与新节点之间搬迁。这些场景的本质,都是对 KV Cache 的异步传输、加载与存储。因此,我们将这些“搬迁”操作抽象为统一的 Backend 接口: 它只负责 kvcache 的异步传输,加载,存储。HybridConnector 的角色也随之升级:它不再只是一个简单的 connector,而是成为 Backend 的异步运行环境;承担了请求生命周期, 链路容错等控制逻辑.
Global Object Cache
大模型时代,除了最常见的 kvcache, 也有越来越多系统, 比如 vl 的 epb 分离, Qwen-omni 的分布式部署, moe 的 eplb 等都需要一个全局共享的内存对象缓存。这些需求共同指向一个目标:构建一个可 随意伸缩, 低延迟 的 Global Object Cache。该 Global Object Cache 应利用模型服务 pod 闲置资源搭建; 定位是 Cache, 不是一个严肃的 Store 系统. 重点是随意伸缩, 类似 p2p 网络, 节点随时加入/离去; 提供了显存/内存到 Cache 快速读写能力, 一定要快! 这与用户体验密切相关.
我们调研了多个方案,最终发现 Mooncake 最符合我们的需求. 但存在 1 个关键问题:Mooncacke Master 元数据未持久化;Master failover 时,所有元数据会丢失,导致服务中断。为了解决这些问题,我们让 Master 运行在 Client 内部,彻底消除单点故障; 基本做法是:
-
MasterClient.Connect("local://local_master_cfg_file_path")时直接在 MasterClient 对象内, 创建一个 WrappedMasterService/MasterService 对象. -
之后
MasterClient.invoke_rpc改为直接调用 MasterService 对应成员函数(service->*ServiceMethod)(std::forward<Args>(args)...); -
MasterService.PutEnd()时将 key, 与当前 master rpc 地址放在某个中心化路由 MetaSyncer 上. 其它对 MasterService 内部 meta map 的增删同样映射到 MetaSyncer 上. 这里 MetaSyncer 仅作路由, 类似 p2p Tracker, 一致性/正确性都不是很重要. -
MasterClient.Query时增加到 MetaSyncer 的查找.
后记
(这一段都是 Qwen 润色的, 哈哈哈哈
AI 真是令人惊叹的技术突破!作为一名多次从零开始踏入全新领域的学习者,我深知其中的艰辛与挑战。还记得在重建我的数学知识体系的过程中,我屡屡陷入这样的困境:一个关键概念无法理解,一个证明步骤卡壳,整个学习进程被迫停滞。那时,我不得不辗转于各大高校数学学院的QQ群,向陌生人发出求助;熬夜撰写邮件咨询;在Math Stack Exchange上苦苦等待专业解答——而每一次,都要经历漫长的等待才能获得一线曙光。AI的出现彻底改变了这一状况。它就像一位学识渊博的导师,24小时随时待命,耐心解答每一个困惑。无论是深奥的数学证明还是晦涩的专业概念,都能得到即时、精准的解释。这种即时获取知识的体验,让我深刻感受到技术对学习方式的革命性改变。
过去一年,我面临的另一重修行,是在喧嚣浪潮中学会与内心的浮躁对话,沉静深耕。说来奇妙,这仿佛成了某种温柔的呼应:2021年数据库领域炙手可热时,我正埋首其中,时常收到各方邀约与咨询;而当我转身投入AI领域,它也恰在此时站上技术浪潮的潮头。相似的际遇再度悄然降临,并非追逐风口,而是提醒我——真正的成长,不在于身处何方,而在于能否在热闹中守住专注,在浮华里沉淀价值。