随着我们 PD 分离系统在线上的推广, 我们观测到了 kvcache 传输逐步成为影响用户 ttft 体验的因素之一. 你可以阅读过往文章了解我们 PD 分离的大致架构, 抛开这些过往背景不言, 现在摆在我们面前的问题比较纯粹: 优化 PD 分离中的 kvcache 传输优化. 在目前线上部署中, 我们 P 节点的 attention tp 是大于 D 节点 attention tp 的:
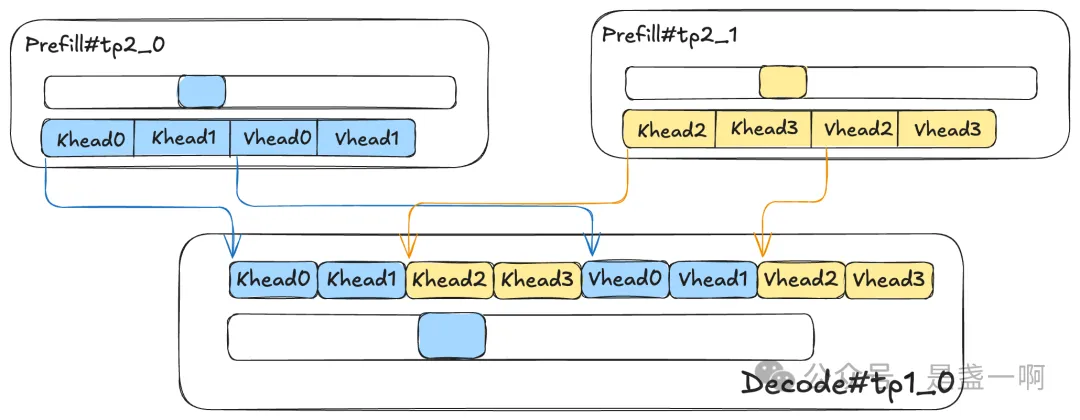
这意味着我们在传输时, 每个 P tp worker 在发起一次 GDR RDMA Write 时, 其内只能包含一个 token 对应的 K/V head 值. 即我们面临的问题具体是: 优化大量小包下 kvcache 传输性能. 既然要优化 RDMA 传输性能, 我第一反应就是 nccl 了, 在我的知识范围内, nccl 始终是 rdma 最佳使用实践了. 毕竟如 GDR: 再深一点 所示, 在传输正确性方面我已经借鉴过 nccl 一次了=
# 目前传输性能 baseline
>>>>>>> method=writebatch min_us=188427.614000 max_us=236119.545000 sum_us=19428281.852000, avg_us=204508.230021
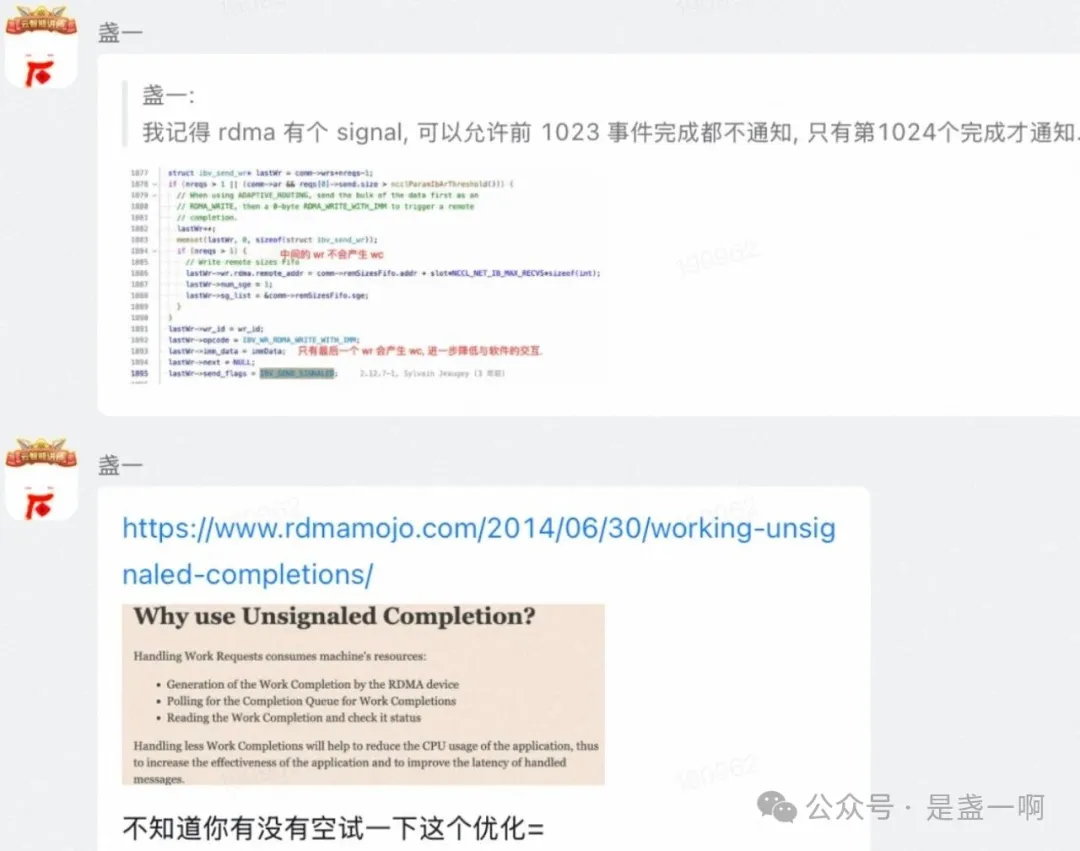
Unsignaled completions
和我们的兄弟团队网络同学一起看了下具体的传输实现, 发现目前 post send 每个 ibv_send_wr 都带有 IBV_SEND_SIGNALED 标记, 这让我想起来 nccl 一个优化:
网络同学在实施了这个优化之后:
# 提升 3.62 倍.
>>>>>>> method=writebatch min_us=51267.882000 max_us=70488.241000 sum_us=5354960.806000, avg_us=56368.008484
这一优化除了减少 cqe 数目的生成之外, 最主要的是还改变了发送的行为. 在 baseline 中每个 ibv_send_wr 都带有 IBV_SEND_SIGNALED 标记, 每次一个 ibv_send_wr 完成之后我们目前所用的网络库都会取出下一个待发送的数据块, 然后进行 ibv_post_send. 在大包场景下, 这样可以确保网卡总是处于繁忙状态中, 不会空闲. 但在我们这种小包场景, 每个 ibv_send_wr 只对应 128 字节, 将导致 cqe 以极高的频率产生, 软件栈开销变得很大. 所以将发送行为改为每次提交一批 ibv_send_wr, 仅这一批中最后一个 ibv_send_wr 带有 IBV_SEND_SIGNALED 标记, 当收到对应 cqe 之后会重复这一行为, 再次提交一批.
还能再快点么?
在完成这一优化的交付之后:
我个人对此也产生了极大的好奇: 我想试试如果我们进一步地在传输链路剥离掉一切与传输无关的开销, 传输性能可以到达什么样的高度?! 也就是我们在传输链路直接裸用 qp 以及 ibv 相关接口:
# 提升 7.19 倍!
>>>>>>> method=writebatch min_us=7802.584000 max_us=8021.546000 sum_us=745098.190000, avg_us=7843.138842
其实这一结果我第一反应是我哪里可能没搞对, 数据可能并没有发送过去; 但是接收端的数据正确性校验确实扎扎实实显示没有问题.
向前! 向前! 向前!!!
再拿到这一结果之后, 我又想到了之前我曾经尝试 nccl 的一种优化但是在我们这里效果不行的手段: 增加发送使用的 qp 数目. 我试过把 qp 数目增加一倍但是只提升了 2% 的侮辱性结果, 这让我郁闷了很久…
于是在 “裸用 qp 以及 ibv 相关接口” 基础之上再次增加一倍 qp 数目:
# 提升了 42.90%
>>>>>>> method=writebatch min_us=4452.392000 max_us=4723.974000 sum_us=425378.284000, avg_us=4477.666147
嗯嗯! 这次终于不郁闷啦.