如 PD 分离中的 GDR 所示, 我们 PD 分离中 Prefill 实例负责完成 prefill, 并将 prefill 生成的 kvcache layer-by-layer 地通过 RDMA Write + GDR(GPU-Direct RDMA) 直接写入到 Decode 实例 d_kv_blocks 中. 目前我们 RDMA Write + GDR 是通过阿里云 ACCL-Barex 库实现:
/**
* Post multiple WRITEs in a batch asynchronously.
* Note that receive peer will NOT be signaled and the send buffers will NOT
* be released after batch completion.
*
* @param datas: payload data to be transferred. It's the user's responsibility
* to ensure that the send buffers are properly registered and both rkeys and
* remote addresses are legal.
* @param done: callback when all WRITEs finished, no matter succeeded or not
* @param done_inline: whether to handle DoneCallback in current IO thread
*/
BarexResult WriteBatch(std::vector<rw_memp_t> &datas, DoneCallback done, bool done_inline);
当回调 done 执行时, 我们认为 RDMA Write 写入完成; 即对于 Prefill 端来说, 其可以释放对 kvcache block 的引用了; 对于 Decode 端来说, kvcache 也已经成功写入到显存, Decode worker 后续发起的 forward 也可以从显存中读取 kvcache 进行计算了. 出于对 memory order 的敏感性, 我还是在代码写完之后向相关同学确认了一下:
Q: 话说你了解对端什么时候返回 ACK 么? 在硬件层的细节. 我看了下对端网卡收到数据包之后发起 PCIE transtion 写 GPU 显存
A: 这里我问我们基础网络的同学,他们的意思是 发送方收到ack的时候,数据已经通过pcie发送到对方显存了
A: 有个更新。。。刚刚找驱动的同学聊了下,gdr场景貌似不能保证,发送端 write 完成后,数据已经写入对端gpu了[流泪] 我们这周讨论一个方案,下周给你同步下
这不由得促使我深入了解下 GDR 的一些细节=
nccl ib 实现
既然想了解 GDR, 那肯定还得是 nccl 实现最为专业啦. 参考 NCCL 源码解读(17): Primitives Simple 了解前提知识点, 这里以 sender, receiver 视角介绍下 nccl ib 与 GDR memory order 相关的实现细节. 在 sender 执行 ncclIbConnect, receiver 执行 ncclIbAccept 之后, 双方便通过 socket 完成了 qpn, mr 等信息的交换:
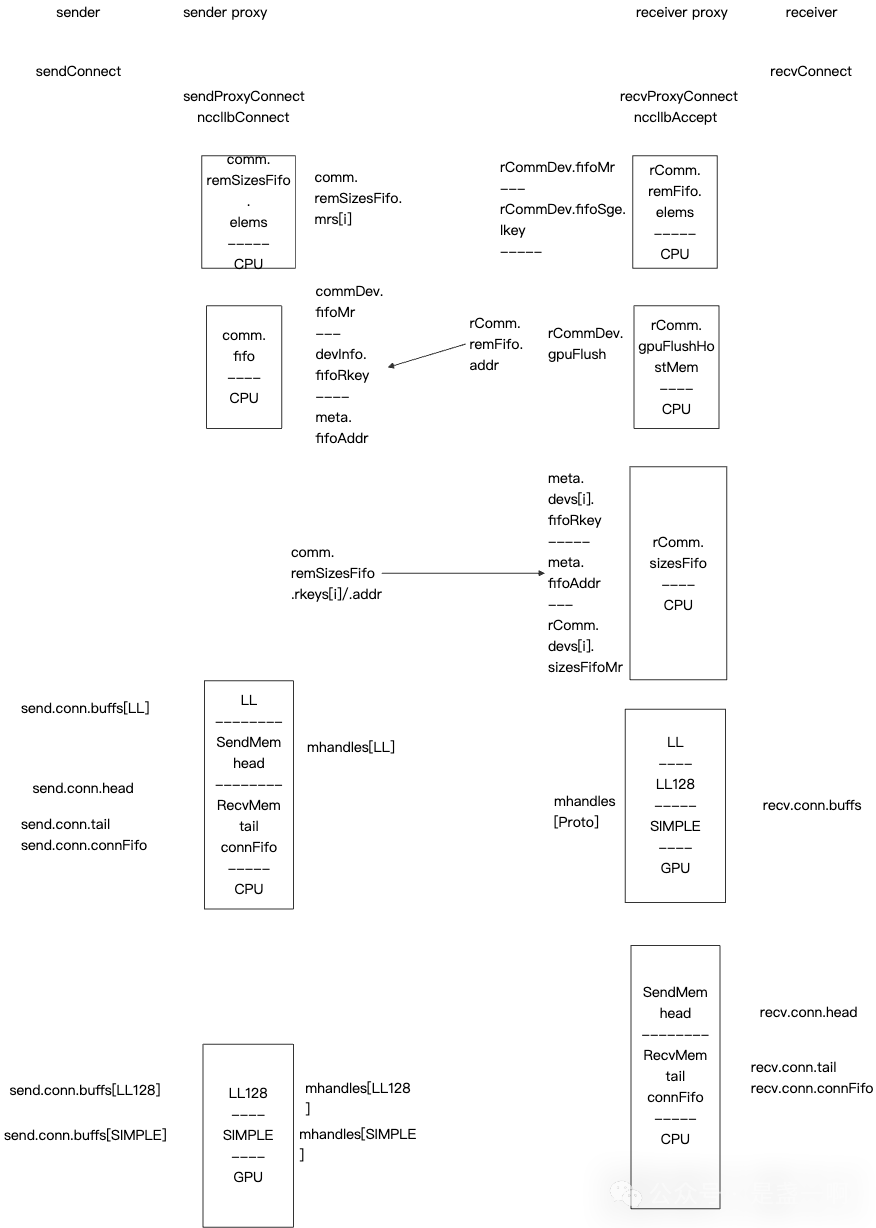
之后 sender 执行 ncclIbIsend, receiver 执行 ncclIbIrecv 来完成数据写入与接收, ncclIbIsend 依赖 ncclIbIrecv 先执行. 在 ncclIbIrecv 中首先填充本地 ncclIbRecvComm.remFifo.elems[slot], 其是 ncclIbSendFifo 类型:
struct ncclIbSendFifo {
uint64_t addr;
uint64_t size;
uint32_t rkeys[NCCL_IB_MAX_DEVS_PER_NIC];
uint32_t nreqs;
uint32_t tag;
uint64_t idx;
char padding[16];
};
这里 ncclIbSendFifo.addr 指向着 receiver 自身显存上某块地址, size 为该块内存的大小; 之后 receiver 通过 rdma write 将 ncclIbRecvComm.remFifo.elems[slot] 写入到 sender 端 ncclIbSendComm.fifo[slot] 中, 这样对于 sender 来说, 其便知道应该将自身显存的数据写入的目的端信息了.
rdma write 1
所以第一个问题来了, 对于 sender 端来说, 其怎么确定 ncclIbSendComm.fifo[slot] 已经被 rnic 写入完成了呢? 怎么防止读取到过时或者不完全的数据呢?
if (slots[0].idx != idx) { *request = NULL; return ncclSuccess; }
nreqs = slots[0].nreqs; // # 1
// Wait until all data has arrived
for (int r=1; r<nreqs; r++) while(slots[r].idx != idx);
__sync_synchronize(); // order the nreqsPtr load against tag/rkey/addr loads below
for (int r=0; r<nreqs; r++) {
if (reqs[r] != NULL || slots[r].tag != tag) continue;
}
从 nccl 实现来看, 是通过 ncclIbSendFifo.idx 字段, 简单来说 receiver 在 rdma write 之前将 idx 设置为某个值, 比如说 33, 之后 sender 检测 idx 是否是 33, 若不是 33 则认为 rdma write 尚未完成, 若是 33 则认为 rdma write 已经完成. 唉, 从我之前学习 C++ memory order 经历来看, 一个经验就是不要依赖具体的代码实现, 硬件细节, 而是从一个标准规范定义的概念起手来搭建整个知识体系, 之后以一个具体的硬件细节实现作为参考. 但不幸的是, 对于 rdma gdr 这块, 我是没有找到规范. 所以我并不确定为啥只通过 idx 字段就可以保证了? 难道真的不会出现 rnic 先写入了 idx 字段, 之后再写入 addr 字段的情况么==
另外既然需要 fence 来 order the nreqsPtr load against tag/rkey/addr loads below, 那么在 # 1 处, 难道不应该也加个 fence 避免 nreqs = slots[0].nreqs order before slots[0].idx != idx 么?
B.T.W 关于通过 poll idx 字段来检测 rdma write 是否完成, 唯一找到一篇正经的参考文章 Broadcom Ethernet Network Adapter User Guide:
No applications are in use that are designed to poll on the last byte-address of the sink buffer to mark the completion for example latency-sensitive RDMA applications.
似乎 poll on last byte-address of the sink buff 是 rdma 惯例=
rdma write 2
之后在 sender 拿到 receiver 发来的完整 ncclIbSendFifo 结构之后, sender 便会通过 rdma write with imm, immData=size 将 sender 端显存上的数据写入到 receiver 端显存. rdma write with imm 会消耗掉 receiver 上一个 receiver request 并产生对应的 cqe, receiver 在 ibv_poll_cq 收到这个 cqe 之后就认为数据已经成功写入显存了, P.S. 这里以 Hopper 架构为例! 后续 receiver 上发起的 kernel 便可以读取这块显存了. 这其实也与我已知的知识点是矛盾的, 从 NCCL GDR Flush Operation 来看, 在 rnic 收到 rdma write 之后, 其:
- 发起 posted pcie write 将数据写入到显存.
- 发起 posted pcie write 将 cqe 写入到内存,
即当 cpu 收到 cqe 时, 第 1 步发起的 posted pcie write 可能并未结束, 数据可能还未写入到显存. 我在 question about GDR Flush Operation on Hopper 发起了一次咨询, 也只得到一个冰冷的回复:
Hopper and later generation GPUs have HW changes that eliminate the need for the flush.
(这让我想起了唐僧问比丘国为何改名小儿城得到的回复…
对于 Hopper 之前的架构, nccl 行为比较符合预期, 其在收到 cqe 之后, 会再通过另一个 qp 发起一次 rdma read 操作, 即从 rnic 角度来说, 其流程:
- rnic1 上 qp1 收到 rdma write with imme, 经 pcei 发起 write 给显存
- rnic1 同时经 pcie 传递 cqe 给 cpu.
- nccl 收到 receive cqe, 之后执行 nccl ib flush. 此时会给 rnic1 qp2 下发 rdma read.
- rnic1 收到 flush 触发的 rdma read, 经 pcei 发起 read 从显存中读取数据, 并将数据写入到内存.
这依赖 rnic1 第 4 步发起的 pcie read 一定要等待第 1 步 pcie write 结束之后才能执行. 这似乎是 pcie 规范:
A Read Request must not pass a Posted Request unless B2b applies
barex 解法
针对文章开头提出的问题, barex 同学解法是在收到 rdma write ack 之后, 发起一次 rdma read 1byte 并在 rdma read 结束之后才执行 done 回调, 这个从 receiver rnic 视角来看, 等同于 nccl ncclIbIflush 操作. 这样好处在于我们应用层不需要任何改动了. done 执行语义现在符合我们在文章开头希望她具有的语义了.