笔者近来一直在参与某个不可名状的项目, 从上到下都很重视, 每天都会拉起 Scrum 会对齐进度, 虽然压力满满但也斗志昂昂. 然后最近项目出现了一个 bug, 此 bug 严重阻塞了各位同学后续进一步验证工作, 已经连续几天在 Scrum 会上被点到. 于是我开始接手这个 bug 的分析定位工作, bug 的修复到很简单, 就是普通的多线程并发问题. 时间来到了当天晚上 7 点左右, 我已经完成了 bug 代码修复工作, 准备凑着晚间 GPU 资源闲置进行一轮压测验证. 然后不幸的事情开始发生了, 压测卡住了! 不再响应请求了! 看了下系统状态 C++ 层流量没有进来, 那只能是阻塞在 Python 层了. 当时就是一阵心虚. 要是阻塞在 C++, 那我真的有十八般武器等着她. 但是 Python, Python 实现细节这块我真的还不太熟. 当时第一念头就是按照之前排查 C++ coroutine 无响应的经验: 先恶补下 Python 实现细节, 之后再使用 GDB 挂住不响应的 Python 进程, 运用 Python 实现细节找出阻塞的各个 asyncio coroutine, 每个 coroutine 的堆栈, 以及相关对象各个字段的状态等. 当时也想着要不先杀掉卡住的进程, 用 pdb 启动看下, 但确实怕问题不再出现或者压测到半夜的时候出现了, 丢失了这宝贵的卡住现场…
总之, 在 4 小时之后我确实分析出问题所在, 一个应该存在的 asyncio coroutine 消失了, 这个 asyncio coroutine 是请求处理链路比较重要的一环, 其从输入 Queue 中拉取请求, 进行一些预处理工作, 之后塞到另外一组 Queue 中, 她消失了确实系统就会不响应了. 消失的原因也很直观, 异常没有处理导致的呗. 然后翻了下日志, 就发现那条异常堆栈就那样懒洋洋地躺在日志中…懊悔! 懊悔!! 为什么!!! 我没有第一时间想到翻翻日志!!!! 仅以此文纪念下我被耽误的 4 个小时!
P.S. 在你尝试使用本文提供的工具之前, 请记得先看下日志, 这毕竟只是 Python, 有一个很成熟的 runtime, 事情可能没有想象中的那种复杂.
定在那
在 DebuggingWithGdb 中, Python 提供了一些 gdb python script, 但这些 script 只是类似 pretty printer, 并不能用来控制 Python 执行流. 而我第一个需求是能让执行流定在一个指定的函数, 指定的行数中, 类似 gdb break 命令, 之后便可以在此处利用 PyFrameObjectPtr.iter_locals 等工具查看一些变量的状态了.
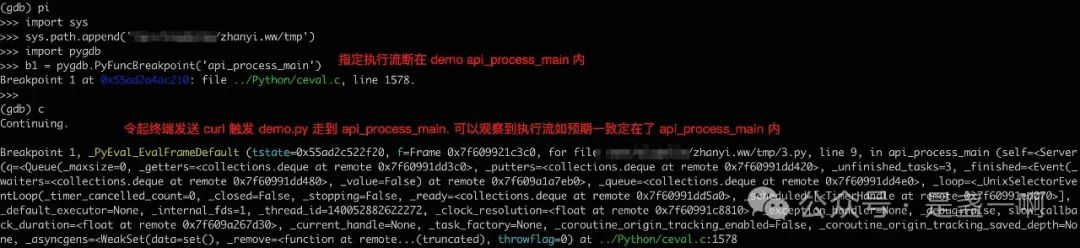
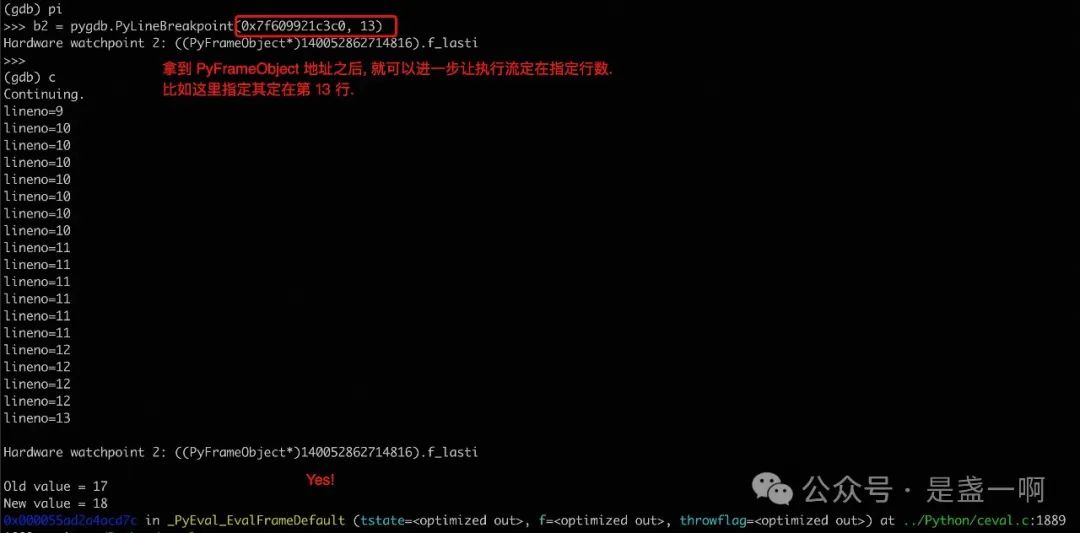
pygdb
pygdb 风格非常像我之前 jegdb 那款工具, 使用 jegdb 来调试内存相关 crash.
# pygdb.py, 适用于 python 3.10.X
import gdb
import sys
pyg = sys.modules['__main__']
class PyFuncBreakpoint(gdb.Breakpoint):
def __init__(self, funcname):
self.bf = funcname
super().__init__('_PyEval_EvalFrameDefault')
def stop(self):
frame = gdb.selected_frame()
f = frame.read_register('rsi').cast(gdb.lookup_type('PyFrameObject').pointer())
frame = pyg.PyFrameObjectPtr(f)
frame_name = frame.co_name.proxyval(set())
if frame_name == self.bf:
return True
else:
return False
class PyLineBreakpoint(gdb.Breakpoint):
def __init__(self, fp, lineno):
self.lineno = lineno
f = gdb.Value(fp).cast(gdb.lookup_type('PyFrameObject').pointer())
self.frame = pyg.PyFrameObjectPtr(f)
super().__init__(f'((PyFrameObject*){fp}).f_lasti', gdb.BP_WATCHPOINT)
def stop(self):
lineno = self.frame.co.addr2line(int(self.frame.field('f_lasti'))*2)
# print(f"{lineno=}")
return lineno >= self.lineno
def frame_print_tacktrace(frame):
frame.print_traceback()
while True:
back_f = frame.field('f_back')
if int(back_f) == 0:
break
back_f = pyg.PyFrameObjectPtr(back_f)
back_f.print_traceback()
frame = back_f
def task_print_traceback(task_pointer):
task_p = gdb.Value(task_pointer).cast(gdb.lookup_type('TaskObj').pointer())
coro_p = task_p.dereference()['task_coro'].cast(gdb.lookup_type('PyCoroObject').pointer())
frame_p = coro_p.dereference()['cr_frame'].cast(gdb.lookup_type('PyFrameObject').pointer())
frame = pyg.PyFrameObjectPtr(frame_p)
task_name = pyg.PyUnicodeObjectPtr(task_p.dereference()['task_name'].cast(gdb.lookup_type('PyUnicodeObject').pointer())).proxyval(set())
print(f"{task_name=}")
frame_print_tacktrace(frame)
def get_field(obj, field):
for k, v in obj.get_attr_dict().iteritems():
k = k.proxyval(set())
if k == field:
return v
return None
# print _all_tasks
def print_all_tasks(all_task_p):
all_tasks = pyg.HeapTypeObjectPtr(gdb.Value(all_task_p).cast(gdb.lookup_type('PyObject').pointer()))
data = get_field(all_tasks, 'data')
for t_weak_ref in data:
t_weak_ref = t_weak_ref._gdbval.cast(gdb.lookup_type('PyWeakReference').pointer())
task_p = int(t_weak_ref.dereference()['wr_object'])
print(f"{task_p=}")
task_print_traceback(int(t_weak_ref.dereference()['wr_object']))
id!
之前在 C++ 项目中, 我就比较喜欢将一些状态对象的地址输出到日志中, 这样在 corefile 或者 gdb alive process 时都省了一堆功夫来找到这些具有关键状态的对象. 在 python 中可以同样如此:

asyncio
如我之前在 为什么协程: 事后追踪 提到的:
还有一个可做的事情是, 针对用户态运行时的特点, 利用 gdb python script 能力扩展 gdb, 比如异步堆栈的展示,
本节演示下如何利用 pygdb print_all_tasks/frame_print_tacktrace 能力来展示当前系统中共有哪些 task, 每个 task 对应的堆栈是什么样子的.
# 本例子即 "为什么协程" 中提到的 asyncio server
def try_get_all_tasks():
try:
import asyncio.tasks
return id(asyncio.tasks._all_tasks)
except Exception: # try failed
return 0
if __name__ == '__main__':
# 如 id 段所示, 记得把一些关键状态对象的地址输出一下.
print(f"{try_get_all_tasks()=}")
loop.create_task(server_main(), name="server")
loop.run_forever()
# python why-coro-server.py
# try_get_all_tasks()=140320073961184
(gdb) pi
>>> pygdb.print_all_tasks(140320073961184)
task_p=140320083962912
task_name='server'
File "why-coro-server.py", line 15, in server_main
task_p=140320081800016
task_name="client-('127.0.0.1', 42628)"
File "why-coro-server.py", line 22, in client_main
task_p=140320081800432
task_name="client-('127.0.0.1', 42674)"
File "why-coro-server.py", line 22, in client_main
>>>
本文一开始提到的问题正是利用 print_all_tasks 发现那个协程不在了…
demo
这是本文演示所用 demo.
import asyncio
from aiohttp import web
class Server:
def __init__(self):
self.q = asyncio.Queue()
async def api_process_main(self, request):
data = await request.json()
future = asyncio.get_event_loop().create_future()
print("this")
print("is")
print("a")
print("print")
print("statement")
await self.q.put((data, future))
resp = await future
return web.json_response(resp)
async def process_request(self, data):
await asyncio.sleep(1)
response = {'status': 'processed', 'original_data': data}
return response
async def worker_main(self):
while True:
data, future = await self.q.get()
try:
result = await self.process_request(data)
future.set_result(result)
except Exception as e:
future.set_exception(e)
def create_web_app(self):
loop = asyncio.get_event_loop()
loop.create_task(self.worker_main())
app = web.Application()
app.router.add_post('/process', self.api_process_main)
return app
def try_get_all_tasks():
try:
import asyncio.tasks
return id(asyncio.tasks._all_tasks)
except Exception: # try failed
return 0
if __name__ == '__main__':
server = Server()
loop = asyncio.get_event_loop()
print(f"{id(server)=} {id(loop)=} {try_get_all_tasks()=}")
app = server.create_web_app()
web.run_app(app, host='127.0.0.1', port=8080, loop=loop)