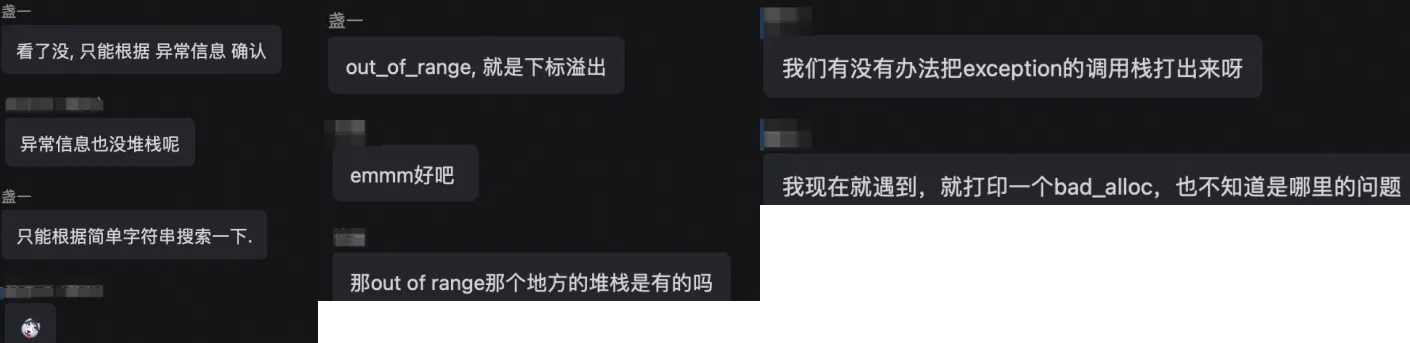
不止一次, 有同学发给我一个 exception what message, 希望我能告知他们这个异常究竟是从哪里抛出的.
经历过C++ 异常与 longjmp: 尘埃落定之后, 我对给异常加上堆栈是有一种模糊可行的想法的, 正好现在有机会抽出了时间实现了这种想法. 关于 C++ 异常机制实现以及相关 ABI 标准, 见前文, 不再在本文中叙述.
基本思想也很简单, 就是我们维护着类型为 std::unordered_map<void*, StackTrace>的全局变量 ex_trace_map. 之后 hook __cxa_throw, 获取此时堆栈, 并将此时异常对象的地址以及堆栈本身保存到 ex_trace_map 中. 并提供相应的接口供用户查询, 比如:
[[gnu::noinline]] void f1(int ex_kind) {
if (ex_kind == kMyEx) {
// throw 会调用 __cxa_throw, 在我们 hook 之后的逻辑中,
// 会获取堆栈, 并将此时异常对象的地址与堆栈保存在 ex_trace_map 中.
throw MyException("I am going now.");
} else if (ex_kind == kStdEx) {
throw std::runtime_error("I bid you all a very fond farewell.");
} else { // kNoEx
std::cerr << "Goodbye." << std::endl;
}
}
int main() {
try {
f1(kMyEx);
} catch (const MyException& e) {
// GetTrace 会查询 ex_trace_map, 找出 e 对应的堆栈信息.
auto sp = GetTrace(e);
std::cerr << sp.ToString() << std::endl;
}
}
具体实现
对 __cxa_throw 的 hook 也很简单, 我们只要在业务代码中重新定义下即可; 这样在 throw 调用 __cxa_throw 抛出异常时, 根据目前链接约定以及符号查询规则, 便会走到我们 hook 后的逻辑中.
namespace __cxxabiv1 {
extern "C" {
__attribute__((visibility("default"))) void __cxa_throw(void*, std::type_info*, void (*)(void*))
__attribute__((__noreturn__));
}
#if 1
void __cxa_throw(void* thrownException, std::type_info* type, void (*destructor)(void*)) {
static auto orig_cxa_throw = reinterpret_cast<decltype(&__cxa_throw)>(dlsym(RTLD_NEXT, "__cxa_throw"));
my_throw_callback(thrownException, type, &destructor);
orig_cxa_throw(thrownException, type, destructor);
__builtin_unreachable(); // orig_cxa_throw never returns
}
#endif
static void my_throw_callback(void* ex, std::type_info* ti, Deleter* deleter) noexcept {
static thread_local bool handling_throw = false;
if (handling_throw) {
return;
}
SCOPE_EXIT { handling_throw = false; };
handling_throw = true;
try {
do_throw_callback(ex, ti, deleter);
} catch (const std::bad_alloc&) {
}
}
// 通过 hook __cxa_throw 确保其调用 do_throw_callback.
static void do_throw_callback(void* ex, std::type_info*, Deleter* deleter) {
auto& ex_map = ex_trace_map();
{
// ExceptionMeta 会获取当前堆栈并保存在 ex_meta 中.
auto ex_meta = ExceptionMeta(*deleter); // catch stack trace.
auto _guard = std::lock_guard<std::shared_mutex>(ex_map.mutex);
auto res = ex_map.map.emplace(ex, std::move(ex_meta));
DCHECK(res.second);
}
// 必须在最后一步变更 deleter, 确保 MetaDeleter 被调用时, ex 一定在 map 中.
// 如果 MetaDeleter 被调用时, ex 不在 map 中, 则会导致 crash.
*deleter = MetaDeleter;
}
// MetaDeleter 会在异常对象析构时调用, 此时将其从 ex_trace_map 中移除.
static void MetaDeleter(void* ex) noexcept {
auto& ex_map = ex_trace_map();
Deleter deleter = nullptr;
{
auto _guard = std::lock_guard<std::shared_mutex>(ex_map.mutex);
auto iter = ex_map.map.find(ex);
DCHECK(iter != ex_map.map.end());
deleter = iter->second.deleter;
ex_map.map.erase(iter);
}
if (deleter) {
deleter(ex);
}
}
}
Q: 这里为啥没有 hook rethrow_exception/__cxa_rethrow?
A: 如下程序所示, 无论是 rethrow_exception 还是 __cxa_rethrow 总是使用同一个异常对象, 此时不需要更新 ex_trace_map.
int main() {
try {
try {
try {
throw std::runtime_error("x");
} catch (const std::exception& e) {
printf("1: %p\n", &e);
throw; // __cxa_rethrow
}
} catch (const std::exception& e) {
printf("2: %p\n", &e);
std::rethrow_exception(std::current_exception());
}
} catch (const std::exception& e) {
printf("3: %p\n", &e);
}
return 0;
}
后记
目前针对异常不带有堆栈信息的处理方法, 我们很多同学会常态化 try catch 异常, 其 catch handler 只是简单输出日志, 之后再次 rethrow 异常:
try {
co_await PrepareSelf(state);
} catch (...) {
auto ex = std::current_exception();
LOG(ERROR) << "Prepare error: " << GetExceptionInfo(ex);
std::rethrow_exception(ex);
}
在有这套机制之后, 我们便不再需要如此, 而是只在业务最顶层/最外层增加对异常的处理, 此时可以输出堆栈等信息方便问题排查.