前言
KuiBaDB 最开始的一个主要想法之一, 便是移除掉 PostgreSQL 中肆意泛滥的全局变量. 我个人认为, 全局变量的肆意使用违背了代码应所见即所得的直观性质, 以一个函数为例, 所见即所得意味着我们可以仅根据该函数的签名便可得知该函数可能依赖的状态, 该函数应在哪些上下文下才能调用等. 但在 PG 中, 在使用调用一个函数之前, 我们不得不了解下这个函数自身的实现, 这个函数所调用子函数的实现, 等等, 主要是要明确这个函数以及其子函数依赖了哪些全局变量, 在使用调用函数时也需要一一确认这些全局变量得到了正确的初始化. 我在这上面被坑到了好多次. 以之前做 Greenplum 分布式 auto analyze 为例, auto analyze 会下发一些 MPP query, 其内会用的 motion node, 而 motion 在 recv 时会在一定情况下检测链接活跃性, 这个检测依赖 MyPort 这个全局变量, 会直接访问 MyPort->port 字段, 这是一个很深的链路, 而恰巧不幸的是一开始 auto analyze 没有初始化 MyPort, 即 MyPort == NULL. 以及 motion recv 检测连接是否活跃也仅是一个非常苛刻的情况下进行, 线下从没遇到过, 线上也仅遇到过一例. 反正最后就在一个风和日丽的下午收到了值班同学反馈 auto analyze crash 了…
还是上面做的 autovacuum, autovacuum 在完成当前节点 vacuum 工作之后, 会调用 dispatchVacuum() 下发 vacuum 到其他计算节点, 大致链路如下:
dispatchVacuum()
CdbDispatchUtilityStatement()
cdbdisp_buildUtilityQueryParms(), 这里会依赖 debug_query_string 这个全局变量, 并且未在函数签名中体现.
pQueryParms->strCommand = debug_query_string;
cdbdisp_dispatchCommandInternal()
buildGpQueryString()
strlen(pQueryParms->strCommand)
autovacuum 一开始也是未初始化 debug_query_string, 即 debug_query_string == NULL, 所以就又一次 crash 了. 好在这次是开发测试阶段就遇到了, 没有在线上酿成悲剧. 不得以, 我使用了 clang LibTooling API 写了个分析 PG/GP 全局变量依赖图的工具:
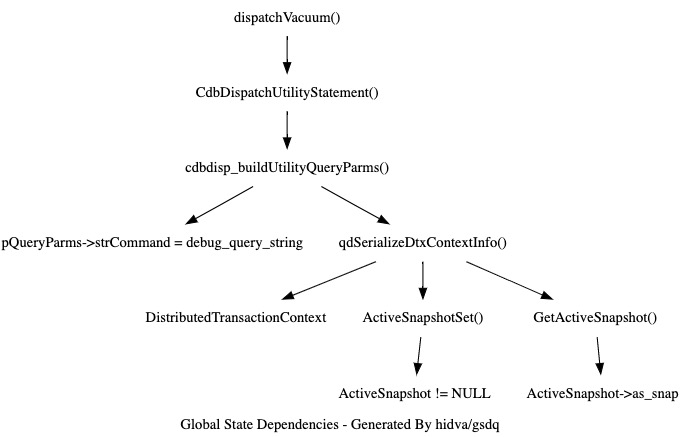
(这又是一个有趣的项目, 确实帮我避免了很多次踩坑, 后面有空会好好介绍下
State
KuiBaDB 中通过在不同的场合使用不同 state struct 移除了所有全局变量. 具体来说, KuiBaDB 使用了 GlobalState 存放着对整个系统可用的状态. 使用了 SessionState 来存放着一个会话相关的状态. 使用了 WorkerState 存放着一个 worker 相关的状态. KuiBaDB 支持 parallel query, 一个 session 可能会使用多个 worker 并行完成查询的处理. 通过这些 state, 我们实现了代码的所见即所得, 对于 KuiBaDB 中任一函数, 只要创建并初始化了函数参数对应的实参, 便可以安心地调用函数, 不必担心函数背后是否还依赖了一些未被初始化的状态. 以 clog 模块 unittest 为例, clog 用于获取 xid 提交状态的 get_xid_status() 接口依赖了 WorkerState, 因此只要我们创建初始化一个 WorkerState 便可以直接调用 get_xid_status:
#[test]
fn t() {
let worker = new_worker();
let xid = Xid::new(1).unwrap();
assert_eq!(XidStatus::InProgress, get_single_xid_status(&worker, xid));
worker.set_xid_status(xid, XidStatus::Committed).unwrap();
assert_eq!(XidStatus::Committed, get_single_xid_status(&worker, xid));
}
StateExt
在 PG 中, 不同模块根据自身需要会定义专属的全局变量. 在 KuiBaDB 中, 不同模块会定义自己的 SessionStateExt, 之后 SessionState 定义会包含这些 SessionStateExt. 比如 namespace 模块定义的 SessionStateExt:
// namespace::SessionStateExt 定义
pub struct SessionStateExt {
search_path: Vec<Oid>,
}
pub struct SessionState {
pub nsstate: NameSpaceSessionStateExt,
}
这里 namespace::SessionStateExt 中 search_path 没有定义为 pub 意味着其他模块只能看到 SessionState::nsstate, 但无法使用 SessionState::nsstate.search_path, 起到点各模块尽量隔离的目的.
WorkerCache
在 PG 中, 在 clog SLRU cache 之上又搭建了一个简陋的 cache: 使用 cachedFetchXid, cachedFetchXidStatus 来缓存最近一次获取的 xid, 以及 xid 的状态. 当其他模块希望获取事务 xid 对应的提交状态时, 其逻辑如下:
if (TransactionIdEquals(xid, cachedFetchXid))
// 哈! 命中了 cache
return cachedFetchXidStatus;
// 木有命中 cache, 调用 clog 接口来查询
xidstatus = TransactionIdGetStatus(xid, &xidlsn);
// 再小心翼翼地把获取的事务状态缓存起来, 万一下次能命中呢
cachedFetchXid = xid;
cachedFetchXidStatus = xidstatus;
这里 cachedFetchXid, cachedFetchXidStatus 作为全局变量, PG 中每个 session 进程都有自己的 cachedFetchXid, cachedFetchXidStatus, 即在 session 之间是不共享的. 在批量更新比较频繁的场景下面, 即存储层吐出的相邻 tuple 往往具有相同的 xmin/xmax, 那么这里这个简陋 cache 命中率还是比较客观的, 举个极端例子:
create table t(i int, j int);
insert into t select * from t1;
select * from t; -- #3
这里由于 t 中所有行都具有相同的 xmin, 所以 ‘#3’ 处 select 只有第一行真正需要调用 TransactionIdGetStatus() 获取状态, 后续行直接通过 cachedFetchXidStatus 即可. 那么 KuiBaDB 怎么整个这种便宜而又实惠的 cache 呢?
首先我们不能将这个 cache 放在 GlobalState 或者 SessionState 中, 因为 xid 状态检测一般都是发生在 worker 中, 放在 GlobalState/SessionState 中, 意味着各个 worker 并发访问 cache 时需要额外的同步语义, 同步带来的开销甚至会远大于从 cache 中取事务提交状态的开销, 就有点不太值当了. 放在 WorkerState 中呢? 可以是可以, 但 WorkerState 是与查询绑定的, 在查询开始时创建, 查询结束时销毁, 意味着这里 cache 只能被单个查询使用. 同一个会话中上一个查询对 cache 的填充无法被下一个查询使用. 所以最终是将 cache 放在 thread local storage 中. 这样我们只需要控制归属于一个 session 的 worker 总是使用相同的 thread 就能达到复用 cache 的目的. 这就是 WorkerCache 的由来:
pub struct WorkerCache {
pub clog: clog::WorkerCacheExt,
}
后续模块只需要将自己的 cache 结构放在 WorkerCache 中便可以参考 clog 模块做法使用 WorkerCache 设施了:
// clog.rs
impl WorkerExt for Worker {
fn get_xid_status(
&self,
xids: &[Xid],
idxes: &[usize],
ret: &mut VecXidStatus,
) -> anyhow::Result<()> {
let mut cache = self.cache.borrow_mut();
}
}
写到这里忽然意识到 PG parallel query 每次都会新建 worker 进程, 查询结束时终止 worker 进程, 即 worker 进程内的 cachedFetchXid 并不能被后续查询使用, 即 PG cachedFetchXid 是只能用于一个查询呢啊.
(2021-06-20 补充) 站在现在的视角来看, WorkerCache 这套机制有点啰嗦了. 之所以显式传递 WorkerCache 是想让调用者明白本函数依赖着一些 cache, 避免 PG 那种隐式依赖着全局变量而导致的不透明问题. 但其实函数隐式依赖着一些 thread local cache 完全可以是对调用者透明的, 毕竟调用者并不需要为这些 thread local cache 做任何初始化工作. 既然如此, 也就没有必要让调用者知道 “本函数依赖着一些 thread local cache” 这一事实了, 徒增心智负担. 所以 KuiBaDB 目前移除了 WorkerCache 这套机制, 而是采用了 std::thread_local!() 的使用姿势来使用 thread local cache. 另外, 我们在为 session, 为 worker 选择 thread 时, 也要考虑到 thread local cache 的存在, 尽量复用 thread 使得 thread local cache 效果最大化.
当前 std::thread_local 提供的 api 比较受限, thread local 变量对应的初始化表达式只能依赖 static 变量. 以 FDCache 为例, 我们不得不先使用一个常数作为 cache capacity, 之后提供了对应的 resize 接口. 即当 Session, Worker 到达了一个新的线程时, 记得调用 init_thread_locals() 重新调整下这些 thread locals 的配置. 当然忘了调用也没啥问题, 此时使用默认设置就是了. 另外当 Session 检测到 guc 发生变化时, 也可以调用 init_thread_locals() 重新配置下 thread locals cache.
RedoState
当前 PG 在 redo 时会将 wal record 中的副作用直接更新到位于共享内存的全局状态中, 而 PG 中基本上所有共享内存中的全局状态都会被锁保护的, 所以 redo() 时也是需要老老实实地获取锁, 更新状态, 释放锁. 但 redo 时系统往往尚未正式开始服务呢, 即是没有必要经历获取锁释放锁这种同步开销的. 其实写到这里, 我忽然想起来 PG Hot standby, redo 是会与用户查询进程并发执行的.. 比如 xlog_redo():
memcpy(&nextOid, XLogRecGetData(record), sizeof(Oid));
// 需要获取锁.
LWLockAcquire(OidGenLock, LW_EXCLUSIVE);
// 然后将 wal record 内的状态更新到全局状态中.
ShmemVariableCache->nextOid = nextOid;
ShmemVariableCache->oidCount = 0;
LWLockRelease(OidGenLock);
所以 KuiBaDB 引入了 RedoState, 用于暂存 redo 过程中 wal record 的副作用, 避免了 redo 过程更新状态需要执行同步逻辑的开销, RedoState 就像是 GlobalState 中字段脱去同步逻辑后的样子:
pub struct RedoState {
// RedoState 中的 nextoid/nextxid 只会被单线程访问, 没必要 Atomic.
nextxid: Xid,
nextoid: Oid,
}
pub struct GlobalState {
// 这里 nextxid/nextoid 会被多个 session 并发访问, 需要 Atomic 同步
pub xid_creator: Option<&'static AtomicU64>, // nextxid
pub oid_creator: Option<&'static AtomicU32>, // nextoid
}
之后对应的 redo 逻辑:
impl Rmgr for XlogRmgr {
fn redo(&mut self, hdr: &RecordHdr, data: &[u8], state: &mut RedoState) -> anyhow::Result<()> {
match hdr.rmgr_info().into() {
XlogInfo::Ckpt => {
let ckpt = get_ckpt(data);
state.set_nextxid(ckpt.nextxid);
Ok(())
}
}
}
}
在 redo 结束之后, 将 RedoState 中状态 apply 到 GlobalState 中:
walreader.storage.recycle(walreader.endlsn)?;
g.oid_creator = Some(make_static(AtomicU32::new(redo_state.nextoid.get())));
g.xid_creator = Some(make_static(AtomicU64::new(redo_state.nextxid.get())));
呃… 写到这里, 我才发现, 当前 redo 时对于事务状态的更新是会直接更新到 GlobalState 中的, 即会经历 clog 模块内置的加锁释放锁同步逻辑的. 再结合 hot standby 功能要求. RedoState 有点多余了…