众所周知, 在执行时, gp 会将查询进行分层处理, 每一层也便是一个 slice, slice 之间通过 motion 节点来完成数据交互. 当前 gp 总会将 slice 调度到集群中每一个计算节点上进行运行. 这其实并不是一个最合适的选择. 以如下查询为例, 在一个共有 3 个 primary segment 的集群中生成了如下查询计划.
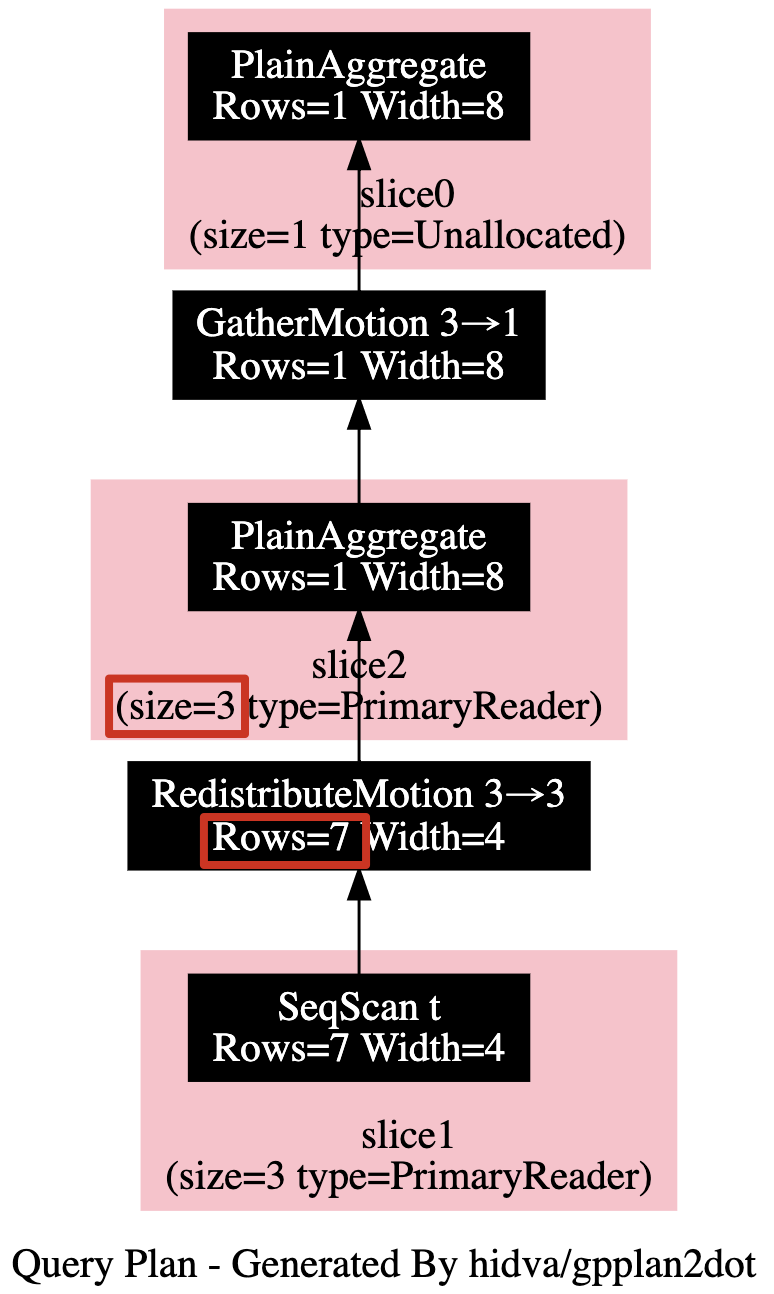
可以看到, slice1 总共只会吐出 7 行, 但 slice2 仍会调度到 3 个 primary segment 执行, 此时每个 primary segment 大概只会处理 2 行左右的数据. 而为此额外的引入 motion, 调度等代价已经远远超过了对这 2 行的处理耗时. 此时完全可以控制 slice2 只调度到 1 个计算节点上运行, 甚至更进一步, 直接将 slice2 与 slice0 进行合并.
另外如果一个查询使用了 OSS 外表, 那么在执行时针对该 OSS 外表的 Foreign Scan 算子总会被调度到所有计算节点上运行, 这里每个计算节点都会分配到, 且只会分配到 1 个 Foreign Scan 算子. 从而来起到一个并行 Foreign Scan 的效果, 来加速查询. 这时 ForeignScan 算子本身会在文件粒度切分扫描任务, 确定自己需要扫描的范围.
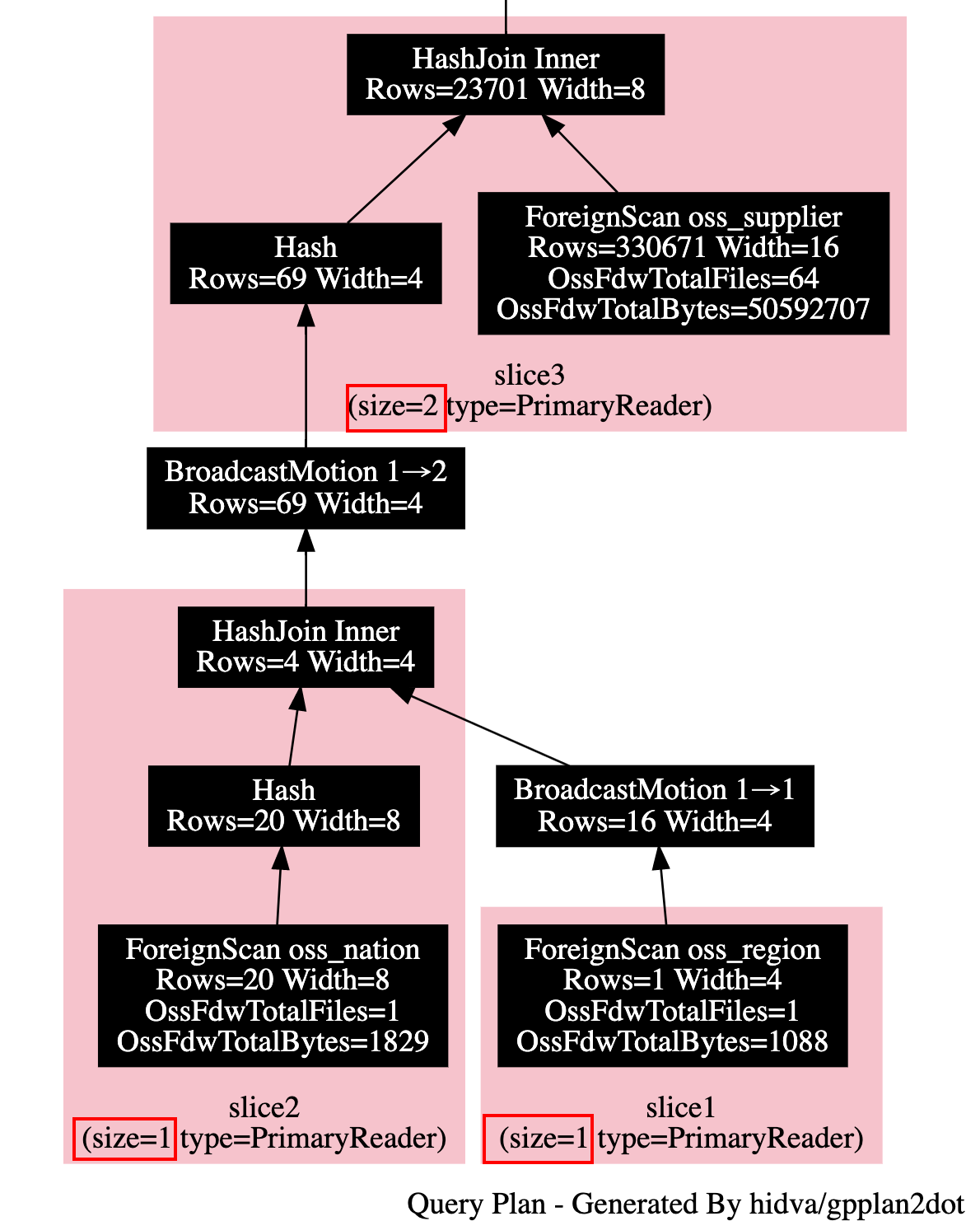
但有些时候, 这一行为并不是最佳选择. 以 TPCH Q02 为例, Q02 所涉及到的表 nation, region 只有几行, 在 OSS 上一般只会用 1 个文件存放. 但当前也会为其创建出多个 ForeignScan 算子, 会使得只有 1 个 ForeignScan 会实际执行扫描. 另外几个 ForeignScan 会启动, 然后发现并没有自己的扫描任务, 然后结束. 就算我们这里强行将 nation, region 切分为多个文件, 每个文件只有 1, 2 行的样子, 这时虽然会有 “并行扫描”, 但为此却引入了额外的数据 shuffle 操作, 得不偿失. 再比如 TPCH Q01 的 lineitem 表, 假设我们的实例具有 3 个计算节点, 每个计算节点 4 个核, 当前 lineitem 表的 ForeignScan 最多也只会有 3 个并发度. 但实际上我们完全可以把并发度提升到 12, 或者提升到 24 个来最大化扫描并发, 从而降低查询时延.
为此我们引入了自适应调度的能力, 会根据子 slice 预估的数据量来调整父 slice 的并行度, 并在可行的时候合并 slice. 对于 Foreign Scan 而言, 会根据外表数据量, 外表在 OSS 上具有多少文件, 以及当前计算节点的个数与规格来确定 ForeignScan 算子的并发度. 在自适应调度能力的加成下, 仍以上面 TPCH Q02 为例, 在一个具有 3 个计算节点的实例上, 如下执行计划所示, 此时在 OSS 上只有 1 个文件的 nation, region 外表的 ForeignScan 只会有 1 个并发. 而对于 oss_supplier 外表, 虽然在 OSS 上有了 64 个文件, 但其总大小只有 48 MB, 所以这里只会为其分配两个并发度.
设计与实现
基本设计思想与改动参考 GP 存储计算分离的一种实现, 这里不再赘述.
继续弹!
当前弹性调度还不是理想情况, 我想象中的情况是优化器能完全感知到弹性调度的事实, 从而从整体上确定 slice 的并发度, 以 Q02 为例, oss_supplier 并发度的增加, 虽然降低了 oss_supplier 自身的扫描耗时, 但由于 oss_supplier 下层是个 boardcast motion 节点, 并发增加意味着下层需要 boardcast 的数据量就上来了.
plan 能感知弹性调度的一个好处, 是可以避免多余的 motion 节点生成. 以文章开头图中计划为例, oss_region 所在的 slice1 到 slice2 是一个 1:1 的 boardcast motion, 所以这个 motion 节点不是必须的. 我们可以把 slice1, slice2 融合成一个 slice.
让 plan 感知到 slice 弹性调度一个小改动是在 create_xxx_path() 时根据实际需要的并发来设置 path 的 path locus 属性. 但如下所述, 影响面太大了, 不可控.
但由于历史原因, 在 GP 中, 无论是优化器, 还是执行器, 都或多或少地或隐式或显式地遵循了同一个约定: 算子的并发度不会超过计算节点的个数. 在弹性调度的开发过程中, 就由于这些情况, 在主体大框架的开发之外, 就是零零散散地适配各个模块在弹性调度事实下的行为了. 虽然 gpdb master 上这一情况已经大大改善, 但还是有一些边边角角的地方…
是时候引入 Concurrency Scaling 了, 早在 2019 年 3 月份就看到 AWS REDSHIFT 引入了 Concurrency Scaling, 会在需要的时候增加更多的节点来对查询进行加速, 当时惊为天人, 心想, 新增节点少不了要把数据也整过去啊, 是怎么秒级把数据拷贝过去的?? 现在在自适应调度框架内也意识到了, 对于那些执行起来不依赖集群状态的 slice, 其实调度到那里都可以执行, 这个时候确实可以临时创建几个节点, 然后将 slice 调度过去.