最近在基于之前提出的一个 POC 设想 GP 存储计算分离的一种实现 为我们 ADB PG OSS 外表加入弹性调度的能力. 当前如果一个查询使用了 OSS 外表, 那么在执行时针对该 OSS 外表的 Foreign Scan 算子总会被调度到所有计算节点上运行, 这里每个计算节点都会分配到, 且只会分配到 1 个 Foreign Scan 算子. 从而来起到一个并行 Foreign Scan 的效果, 来加速查询. 这时 ForeignScan 算子本身会在文件粒度, 对于某些特殊格式, 如 ORC/PARQUET 会在块粒度切分扫描任务, 确定自己需要扫描的范围.
站在现在的视角来看, 这一行为多少有点死板了. 以 TPCH Q02 为例, Q02 所涉及到的表 nation, region 只有几行, 在 OSS 上一般只会用 1 个文件存放. 但当前也会为其创建出多个 ForeignScan 算子, 会使得只有 1 个 ForeignScan 会实际执行扫描. 另外几个 ForeignScan 会启动, 然后发现并没有自己的扫描任务, 然后结束. 就算我们这里强行将 nation, region 切分为多个文件, 每个文件只有 1, 2 行的样子, 这时虽然会有 “并行扫描”, 但为此却引入了额外的数据 shuffle 操作, 得不偿失. 再比如 TPCH Q01 的 lineitem 表, 假设我们的实例具有 3 个计算节点, 每个计算节点 4 个核, 当前 lineitem 表的 ForeignScan 最多也只会有 3 个并发度. 但实际上我们完全可以把并发度提升到 12, 或者提升到 24 个来最大化扫描并发, 从而降低查询时延.
为此我们针对 ForeignScan 算子引入了弹性调度的能力, 会根据外表数据量, 外表在 OSS 上具有多少文件, 以及当前计算节点的个数与规格, 再结合当前系统的负载来确定 ForeignScan 算子的并发度. 在弹性能力的加成下, 仍以上面 TPCH Q02 为例, 在一个具有 3 个计算节点的实例上, 如下执行计划所示, 此时在 OSS 上只有 1 个文件的 nation, region 外表的 ForeignScan 只会有 1 个并发. 而对于 oss_supplier 外表, 虽然在 OSS 上有了 64 个文件, 但其总大小只有 48 MB, 所以这里只会为其分配两个并发度.
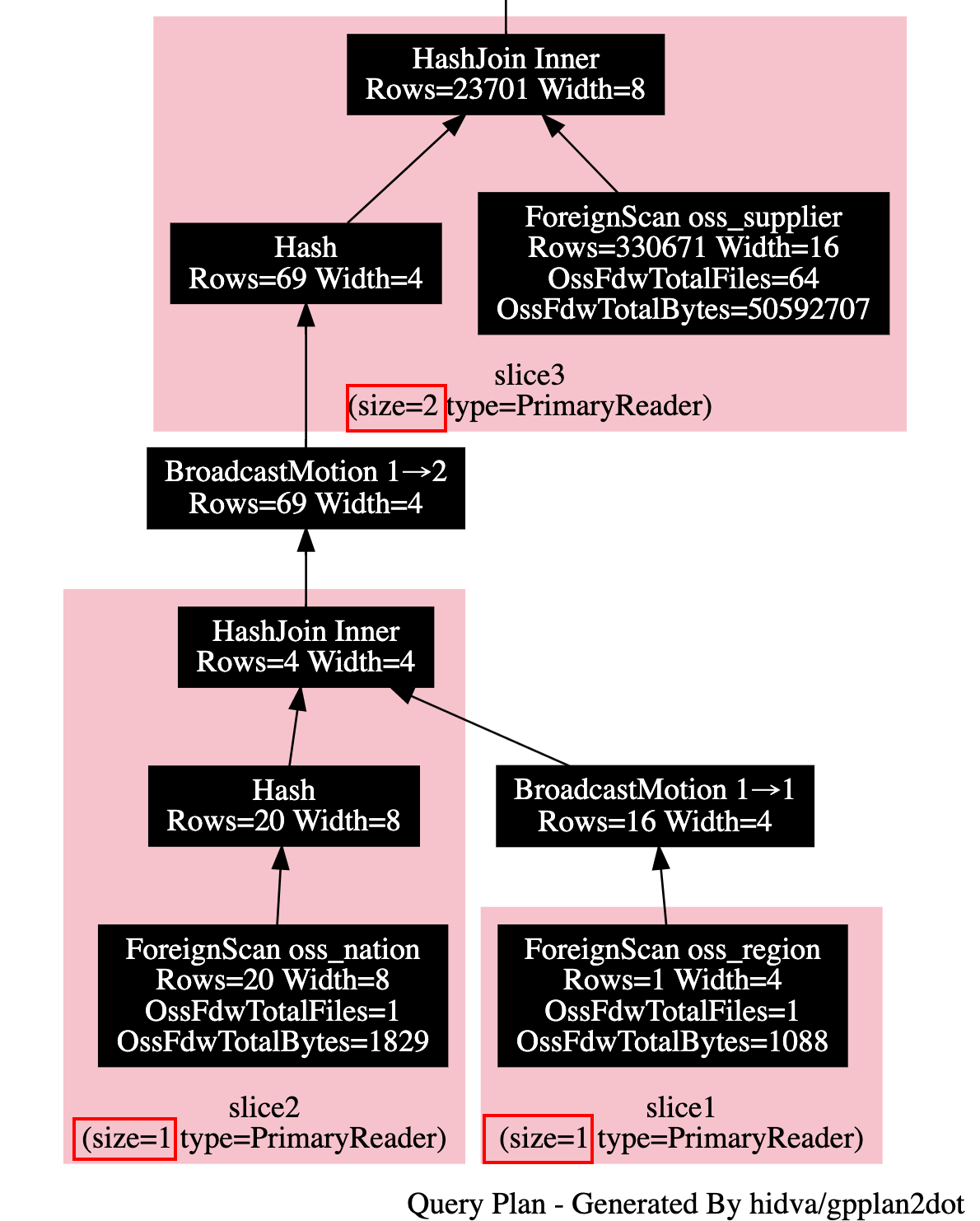
但还不是理想情况, 我想象中的情况是优化器能完全感知到弹性调度的事实, 从而从整体上确定 ForeignScan 的并发度, 以 Q02 为例, oss_supplier 并发度的增加, 虽然降低了 oss_supplier 自身的扫描耗时, 但由于 oss_supplier 下层是个 boardcast motion 节点, 并发增加意味着下层需要 boardcast 的数据量就上来了. 当前只会根据 oss_supplier 自身信息结合系统整体状态来确定 ForeignScan 并发度多少, 多少还是有点片面了. 更进一步的说, 对于非 ForeignScan 之外的其他 plannode, 优化器也完全可以结合 plan node 预估需要处理的行数来确定每个 plan node 的并发度. plan 能感知弹性调度的一个好处, 是可以避免多余的 motion 节点生成. 以文章开头图中计划为例, oss_region 所在的 slice1 到 slice2 是一个 1:1 的 boardcast motion, 所以这个 motion 节点不是必须的. 我们可以把 slice1, slice2 融合成一个 slice.
扯远了, 还是回到文章主题. 总之在我完成弹性调度的开发之后, 接下来就要实测一下效果了, 这里使用了 TPCH 100G 的一个环境. 一路高歌猛进, 情况一片大好, 尤其是 Q1, 更是有了 4 倍以上的提升. 直到遇到了 Q4, 结果不对了! (等等, 这好像并没有猛进多远啊==). 预期结果是:
1-URGENT |1051977
2-HIGH |1052987
3-MEDIUM |1052921
4-NOT SPECIFIED|1051493
5-LOW |1052194
但实际结果
1-URGENT |1050837
2-HIGH |1051829
3-MEDIUM |1051727
4-NOT SPECIFIED|1050339
5-LOW |1051081
而且悲剧的是, 每次运行, 实际结果都不一样. 这让我慌得一B, 由于历史原因, 在 ADB PG 中, 无论是优化器, 还是执行器, 都或多或少地或隐式或显式地遵循了同一个约定: 算子的并发度不会超过计算节点的个数. 在弹性调度的开发过程中, 就由于这些情况, 在主体大框架的开发之外, 就是零零散散地适配各个模块在弹性调度事实下的行为了. 结果的不对意味着肯定是 ADB PG 有一处没有做好弹性调度的适配工作. 这意味着我接下来可能要苦兮兮地在一大坨代码中精准地找到这究竟是那一处了.
首当其冲被怀疑的是 Motion 对 EOS(end of stream)的处理, 在 ADB PG 中, motion 实现了数据的 shuffle 工作, 其将发送方的数据按照要求或广播或hash 分布发送给不同的接收方. 针对每一个发送方, 在自身所有数据发送完毕之后, 会再发送一个 EOS 标记来告诉接收方自己完事了. 接收方在收到所有发送方的 EOS 之后便知道所有的发送方都完事了. 一个潜在的疑点是接收方对 “所有发送方都 EOS 了” 这一事实的判定, 如果接收方默认了发送方数目最多只会有实例中计算节点数目那么多, 那么就会导致接收方提前认为 “所有发送方都 EOS 了”. 比如实例中共有 3 个计算节点, 对于表 oss_lineitem 的扫描会有 12 个并发 worker. 由于接收方对 EOS 的错误认知会导致任意 3 个并发 worker 发送了 EOS 之后, 接收方便不再处理剩余 9 个 parallel worker 吐出的数据. 考虑到每次运行先结束的 worker 都不确定, 也就显然地导致了结果不确定. 这与我们看到的事实还是非常类似的. 所以我满怀欣喜与信心地 gdb 了一个 parallel worker.
满怀失望地发现查询并没有在预计时间内结束, 哪怕 12 个 parallel worker 除了被 gdb 的剩下 11 个都已经结束了运行. 也就是说接收方始终会真正地等到所有的发送方都发送了 EOS 之后才会返回. 与此同时结合代码看了下, 也确实是这样.
接下里就没啥其他好怀疑的了, 我已经准备在执行结束, 打印每个 plan node 的输入行以及输出行数. 来具体比较一下, 究竟是哪个 plan node 弄丢了我的行数, 之后再看下 plan node 的具体逻辑. 然后在 TPCH 1G 环境上跑了下, 惊喜地发现这时并没有结果丢失的现象, 反复运行多次都是. 而且忽然发现 TPCH 1G 下的 Q4 计划与 TPCH 100G 也有所不一样. TPCH 1G 的执行计划片段如下:

而 TPCH 100G 的执行计划对应片段则是:
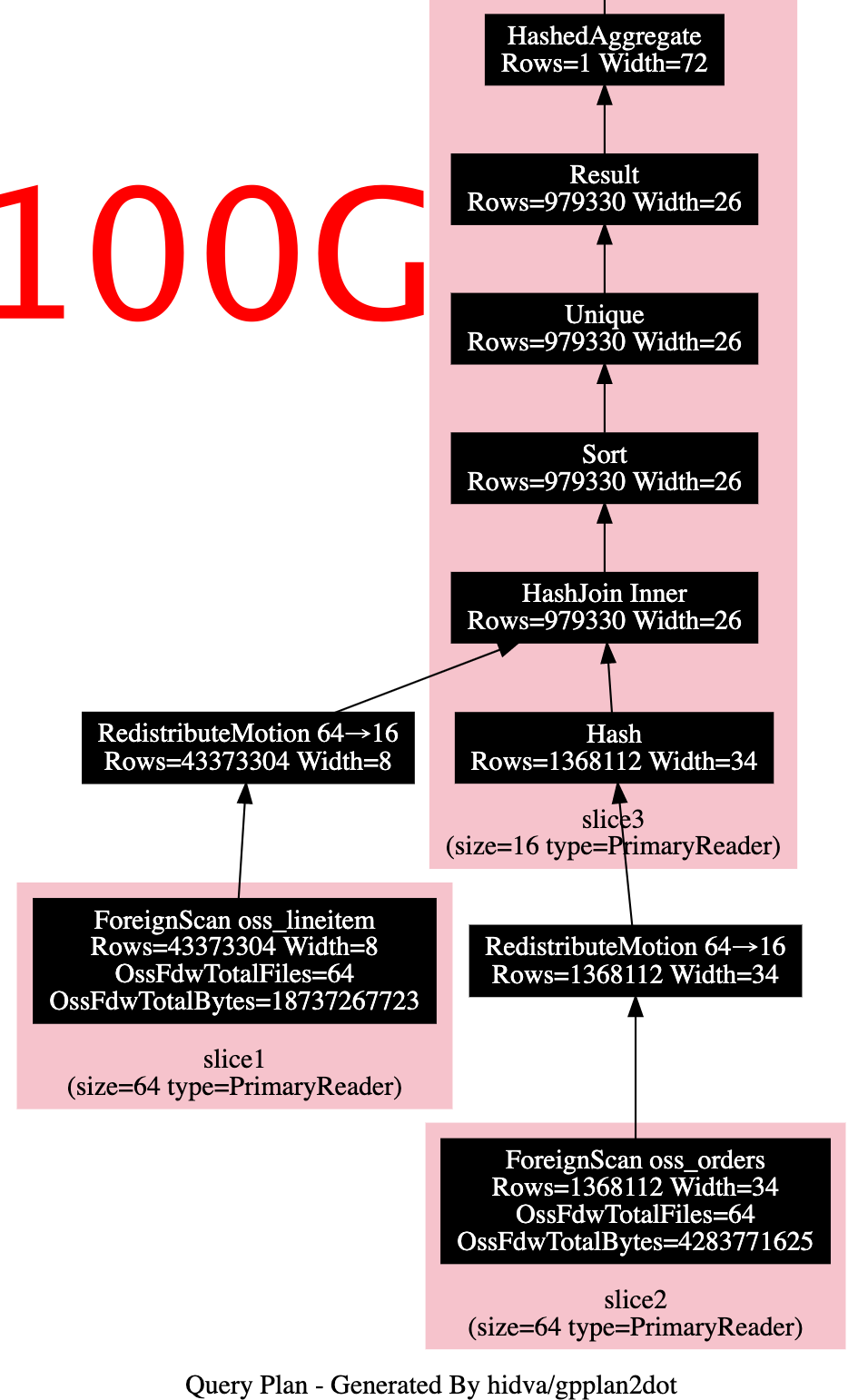
也即 100G 会先使用 1 个普通的 hash inner join, 然后再根据 (oss_orders.gp_segment_id, oss_orders.ctid) sort unique 过滤掉 inner join 之后 oss_orders 重复的行. 之后再次基础上执行两阶段的 hash agg 最终得到结果. 这里 gp_segment_id, ctid 实际上对于本地表更有意义一点, 分别指定了本地表所在的计算节点, 以及当前行在当前计算节点的位置, 也即使用 gp_segment_id, ctid 可以精确的确定分布式表的一行数据.
等等!!! gp_segment_id!!! 在弹性调度上下文里, 这无疑是最敏感的字段了. 实际上也确实是因为未正确处理好 gp_segment_id 在弹性调度下的行为导致了 Q4 结果不对的情况. 准确来说, 应该是 (gp_segment_id, ctid) 这一组合的行为未做好适配的工作. 外表嘛, 其并没有真正的 ctid 字段, 所以 ForeignScan 算子会简单地使用一个累加值为其吐出的每一行赋值一个 ctid. 在弹性调度之前, 每个计算节点都有且只有一个 ForeignScan 算子, 所以外表的每一行仍具有一个唯一的 (gp_segment_id, ctid) 组合. 但在弹性调度之后, 一个计算节点上可能会有多个 ForeignScan 算子, 此时意味着一个 (gp_segment_id, ctid) 组合可能对应着外表的多个行了. 这由此导致了 unique sort 错误地丢弃了很多行.
临时性地关闭了 sort 算子的生成, 使得 tpch 100G 下 q4 也使用 1g 时的计划便可以发现结果没问题了. 那么接下来的工作便是适配下弹性调度下 ctid 的生成算法咯~ 之所以不改动 gp_segment_id 是因为 gp_segment_id 还影响 direct motion, 暂时还不能瞎搞.