COW 机制
-
首先 COW 机制是有一点优点的,主要是大尺度字符串下,如:
{ std::string str (10 * 1024 * 1024,'c'); std::string str1 = str; PP_QQ_LOG_D("std::string: %s",str1.data() == str.data() ? "采用 COW" : "没采用 COW"); folly::fbstring str2 (10 * 1024 * 1024,'c'); folly::fbstring str3 = str2; PP_QQ_LOG_D("folly::fbstring: %s",str2.data() == str3.data() ? "采用 COW" : "没采用 COW"); } { std::string str (10 * 1024 * 1024,'c'); std::string str1; PP_QQ_LOG_D("Time: %lu ns",ExecuteTimeGet(7,1000,[&] () noexcept {str1 = str;})); } { folly::fbstring str (10 * 1024 * 1024,'c'); folly::fbstring str1; PP_QQ_LOG_D("Time: %lu ns",ExecuteTimeGet(7,1000,[&] () noexcept {str1 = str;})); } return 0;# 运行结果: std::string: 没采用 COW folly::fbstring: 采用 COW Time: 2982838772 ns Time: 775917112 ns我总感觉这个说法很勉强 @_@
-
缺点1,false sharing;由于在 COW 的实现中,引用计数经常和一些只读属性(包括 size,capacity, 字符串内容)在一起,所以可能会加载到同一 cache line 中,所以当引用计数更新时会导致 false sharing.
-
缺点2,原子操作带来的同步副作用,参考’MESI 协议’.
对 COW 机制友好
-
若是新字符串对象肯定会被写,则不使用 COW 机制;因为由于新字符串对象会被写,所以内存分配,复制 是躲不过,此时若仍然使用 COW 机制,则最多是将内存分配,复制延迟;但此时也会带有 COW 机制所有 的缺点.即:
- 使用 COW 机制,消耗的时间 = 内存分配复制 + COW机制缺点带来的时间;
- 不使用 COW 机制,消耗的时间 = 内存分配复制;
所以如何不使用 COW 机制呢:
-
更改构造新字符串对象时的构造姿势:
std::string str1 (521,'c'); std::string str2 (str1); // 这里会使用 COW 机制 // 这里肯定不会使用 COW 机制,并且 str3 == str2; std::string str3 (str1.data(),str1.size()); -
利用
basic_fbstring(value_type *s, size_type n, size_type c,AcquireMallocatedString a); 这里与常规的实现代价完全一致,因为这里并不会有任何原子操作.folly::fbstring str1(521,'x'); void *ptr = malloc(str1.size() + 1); CHECK(ptr == nullptr); memcpy(ptr,str1.data(),str1.size()); (static_cast<char*>(ptr))[str1.size()] = '\0'; folly::fbstring str2(p,str1.size(),str1.size() + 1,AcquireMallocatedString{});
前言
- 本次源码分析基于 commitid:60088aaa3981d97f303a079b500dd03e2ae966b7;
FBString 是啥
- 100% 兼容
std::string.更有效率的一种字符串实现.
basic_fbstring与fbstring_core
fbstring_core;负责字符串对象中字符串的存放.basic_fbstring;其内含有一个fbstring_core对象,并且在fbstring_core提供的接口之上 实现了std::string定义的所有接口.- 当需要自定义
fbstring_core时,只需要按照下面的接口实现一份fbstring_core类,然后据此初始 化basic_fbstring即可.
API Reference: fbstring_core
template <class Char>
class fbstring_core_model;
TPARAM:Char;指定了字符串中字符的类型.
构造析构
fbstring_core_model();
fbstring_core_model(const fbstring_core_model &);
fbstring_core_model(fbstring_core_model &&);
~fbstring_core_model();
- 没啥可说的.
fbstring_core_model(const Char *const data, const size_t size);
- 构建一个字符串,其出事内容由
[data,data + size)确定的区间来填充.
fbstring_core_model(Char * const data,const size_t size,const size_t allocatedSize,AcquireMallocatedString);
- 当调用此函数时,
data指向着malloc(allocatedSize)分配的内存,size表明在data指向的 缓冲区中已经存放的字符个数(不包括\0字符).并且满足allocatedSize >= size + 1 && data[size] == '\0'. - 此时表明将
data指向的内存的接管权交给fbstring_core_model,由fbstring_core_model负责内存管理.
swap()
void swap(fbstring_core_model &rhs);
- 没啥可说的.
data()
const Char* data() const;
- 返回一个指针,指向着
fbstring_core_model内部存放字符数组的内存块. - 调用者确定不会通过该指针来修改
fbstring_core_model对象. - 该指针一直有效直至下一次调用了 non-const 成员函数.
mutable_data()
Char* mutable_data();
- 返回一个指针,指向着
fbstring_core_model内部存放字符数组的内存块. - 调用者可能会通过该指针来修改
fbstring_core_model对象,所以要是fbstring_core_model采用了 COW 机制,那么是时候 detach 了! - 该指针一直有效直至下一次调用了 non-const 成员函数.
c_str()
const Char * c_str() const;
- 与
data()一致,除了返回的指针指向着的内存确保是\0结尾的! -
若
fbstring_core的实现采用了延迟追加\0,那么是时候追加该字符了. - 题外话!能不能同时实现延迟追加
\0与 COW 机制呢,我觉得是可以的,第一:不能因为该函数修改了字符串 就进行 Copy 操作,因为这样会修改data()的返回值,而且c_str()被注释为const的!即违背了data()的语义.如果不能进行 Copy 操作,那么只能直接在原地追加,而且这里也不会造成数据竞争之类的问题,因为 COW 特性.
shrink()
void shrink(size_t delta);
- 与
std::string::resize(size() - delta)同义.
expand_noinit()
Char* expand_noinit(size_t delta, bool expGrowth);
- 在当前字符串之后额外分配
delta字节的内存,称作 expanded region,expanded region 未被初 始化,并且\0结尾. PARAM:expGrowth;If expGrowth is true, exponential growth is guaranteed.没怎 么明白啥意思,不过看代码应该是当expGrowth为false时,要多少内存分配多少内存,不能多分配!当expGrowth为true时,可以在请求的内存基础之上分配多余的内存.RETURN;expanded region 的地址,调用者可以利用该地址来填充 expanded region 区域.
push_back()
void push_back(Char c);
-
呃…就是追加一个字符.
-
题外话!不是很清楚为啥 folly 要把这个接口单拿出来
size()
size_t size() const;
- 返回当前对象中存放字符的个数.
capacity()
size_t capacity() const;
- 在不重新分配内存的情况下,当前字符串对象所能存放的字符个数.
isShared()
bool isShared() const;
- 若返回真,则表明当前
fbstring_core对象与其他fbstring_core对象共享着底层字符存储.
reserve()
void reserve(size_t minCapacity);
- 确保当前字符串仅被其自身引用,而且至少可以存放
minCapacity个字符.
默认fbstring_core的实现
三种存储策略
-
首先看一下
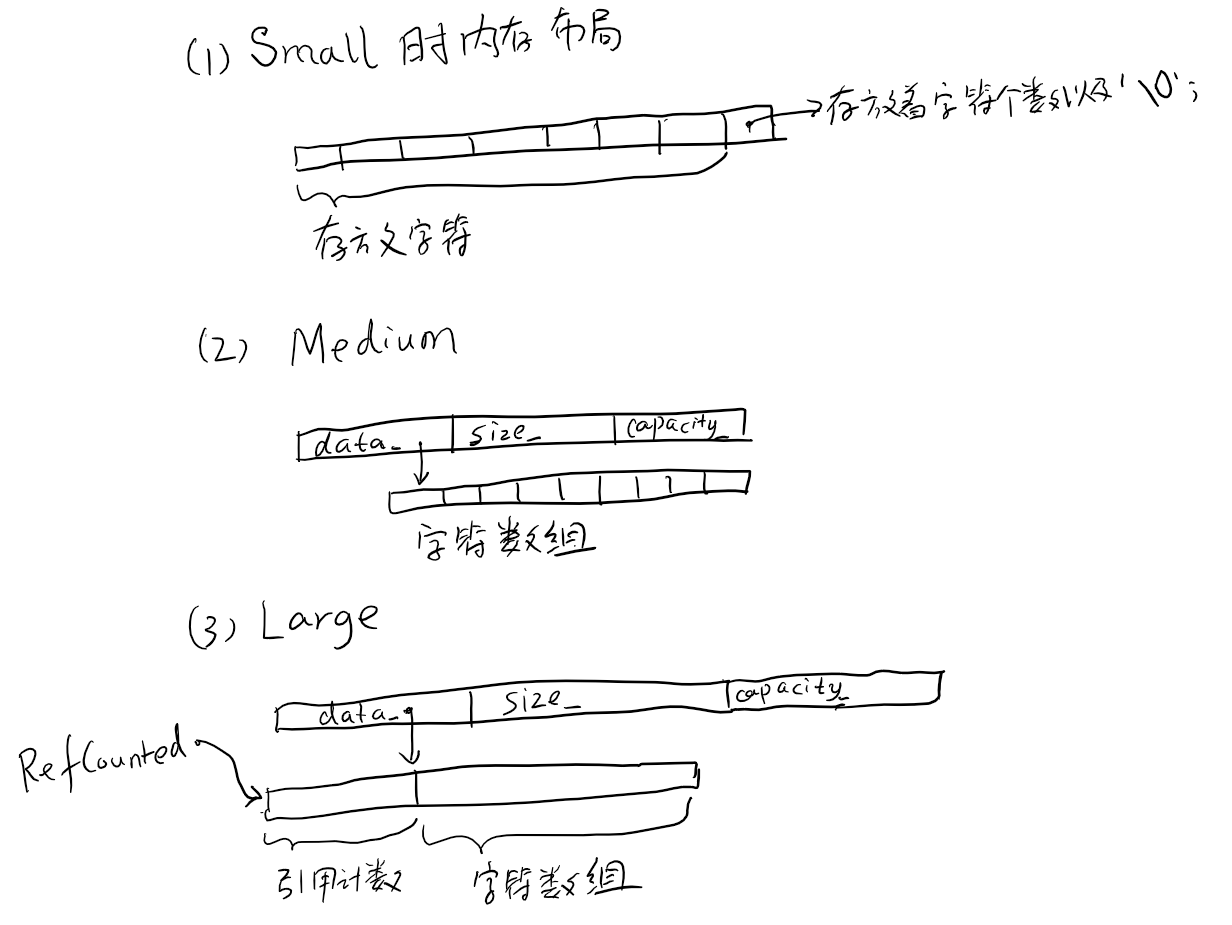
fbstring_core类的数据成员:struct MediumLarge { Char * data_; size_t size_; size_t capacity_; } static_assert(sizeof(size_t) == sizeof(Char*)); static_assert(sizeof(MediumLarge) == 3 * sizeof(Char*)); static_assert(sizeof(MediumLarge) % sizeof(Char) == 0); static_assert((sizeof(size_t) & (sizeof(size_t) - 1)) == 0); // sizeof(size_t) 必须是 2 的 n 次方. union { Char small_[sizeof(MediumLarge) / sizeof(Char)]; MediumLarge ml_; }; enum : size_t { lastChar = sizeof(MediumLarge) - 1, // lastChar / sizeof(Char) == sizeof(MediumLarge) / sizeof(Char) - 1; maxSmallSize = lastChar / sizeof(Char), maxMediumSize = 254 / sizeof(Char) }; - 三种存储策略:
- Small;在字符串中的字符不超过
maxSmallSize时,存放在栈(small_数组)中. - Medium;在字符串的字符不超过
maxMediumSize时,存放在使用malloc()分配的空间中,并且 不采用 COW 机制,大概 folly 认为此时原子操作的时间已经超过分配内存和复制字符串的总时间了 吧. - Large;除此之外,字符串存放在使用
malloc()分配的空间中,并采用 COW 机制!
- Small;在字符串中的字符不超过
-
category,存放着当前字符串对象采用何种存储策略;其与 capacity 一起存放在
MediumLarge::capacity_上;如下: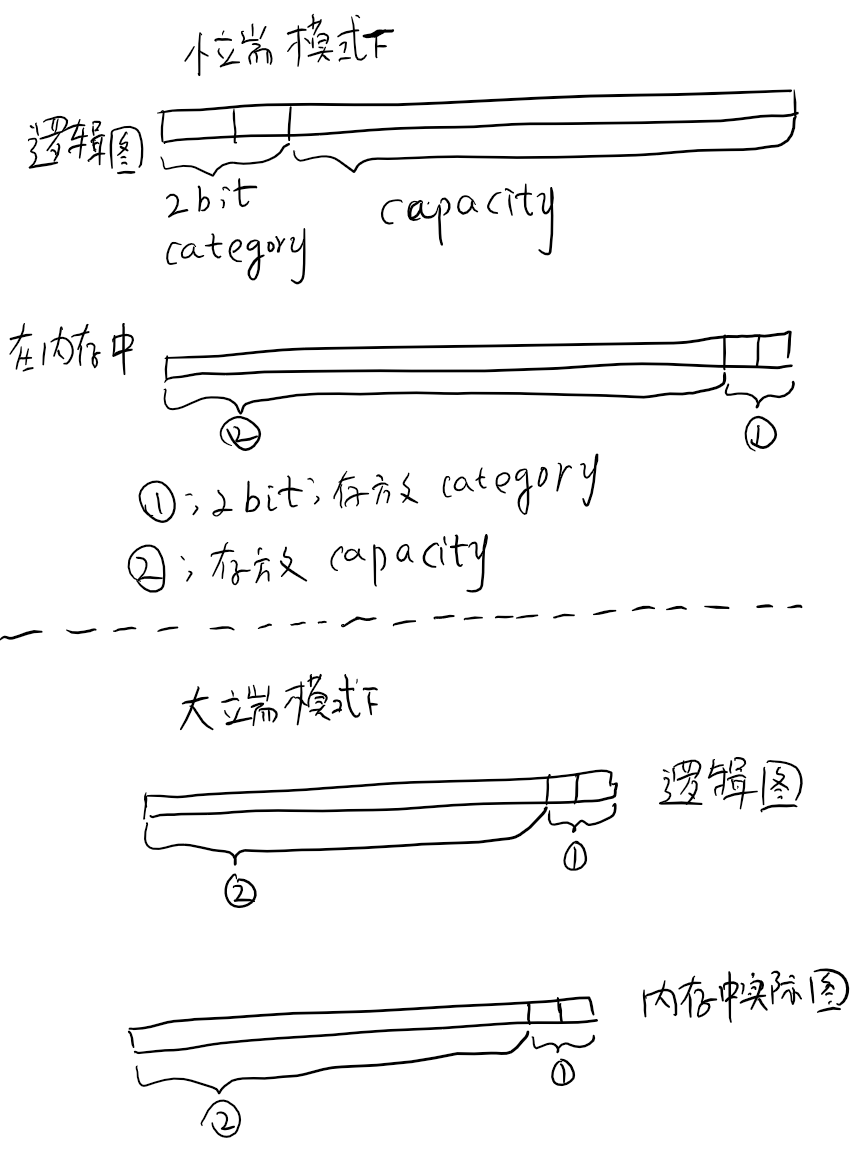
- 最后可以再看一下
MediumLarge::capacity()与MediumLarge::setCapacity()的实现.
当为 Small 时
-
当
fbstring_core为 Small 时,字符串直接存放在small_数组中;那么此时字符串中字符个数 size 在哪???! - 当前字符个数 size 存放在
small_的最后一个元素中,并且并没有直接存放 size 的值,而是存放着maxSmallSize - size的值.- 这时候注意 category 也是存放在
small_的最后一个元素的,不过当存储策略为 Small 时, category 总是为 0!所以此时在设置 size 时不应该影响了 category 的值!
- 这时候注意 category 也是存放在
-
为什么存放的是
maxSmallSize - size的值呢?!首先考虑下当直接存放 size 的值时,这样由于要为\0预留空间,所以最多只能存放maxSmallSize - 1个字符.但是当将maxSmallSize - size的值存放起来之后,这是可以存放maxSmallSize个字符,因为此时maxSmallSize - size == 0, 所以small_的最后一个元素在存放 size 的同时也起到了\0的作用.666啊~ - 这时候可以看一下
fbstring_core::setSmallSize()与fbstring_core::smallSize()的实 现.
当为 Large 时
RefCounted
struct RefCounted {
std::atomic<size_t> refCount_;
Char data_[1];
};

data_;利用了数组类型对象会自动转化为指针类型,data_实际上指向着变长字符数组.
总结
basic_fbstring 的实现
std::string 的 COW 实现
-
std::string 采用了 COW 机制,但是其又在某些时刻会将
std::string对象设置为 unshareable! 即此时根据该对象创建新std::string对象时,会导致内存分配与字符串复制动作.如:std::string s1{"HelloWorld"}; // s2,s1 共享内存. std::string s2{s1}; // 调用了 operator[],此时 s1 会首先 fork,然后变为 unshareable 状态. char ch = s1[0]; // 由于 s1 unshareable,所以此时 s3,s1 未共享内存;即 s3 自己会分配内存,并拷贝 s1 的字符串. std::string s3{s1}; -
导致
std::string对象变为 unshareable 的操作见下,这些操作有一个共同点就是均会返回内部地址, 而且调用者均可通过这些内部地址来修改字符串的内容.char& operator[];char& at[];begin(),end();iterator insert(...);iterator erase(...);
QByteArray 的 COW 实现
-
延迟 fork.如下:
// ByteRef 表明是对 ByteArray 中某处下标上字节的引用. // 通过运算符重载确保仅在需要的时候才通知 ByteArray 进行 fork 操作. class ByteArray::ByteRef { friend class ByteArray; ByteArray &a; size_t i; ByteRef(ByteArray &a,size_t idx); public: ByteRef& operator=(unsigned char c); ByteRef& operator=(const ByteRef &b); operator unsigned char() const; bool operator ==(unsigned char c) const; bool operator !=(unsigned char c) const; bool operator >(unsigned char c) const; bool operator >=(unsigned char c) const; bool operator <(unsigned char c) const; bool operator <=(unsigned char c) const; }; struct ByteArray { ByteRef operator[] (size_t i); };- 其实我觉得没有必要,应该由调用者来负责,在只读的时候调用那些
const方法,在需要修改的时候调 用非const方法.
- 其实我觉得没有必要,应该由调用者来负责,在只读的时候调用那些
-
并没有像
std::string那样采用 unshareable 的做法.
终于整完了,好几天了都
转载请注明出处!谢谢